Stapels PDF’s, één workflow: zo leest AI documenten zodat jij dat niet hoeft

Documentverwerking is in vrijwel elke sector een terugkerend vraagstuk. Denk aan een financieel analist midden in een overnametraject, die honderden pagina’s aan jaarrekeningen en contracten moet doorspitten. Vaak van tientallen partijen, elk met een eigen opmaak. Of een logistiek coördinator die dagelijks inkomende vrachtdocumenten verwerkt: ladingbrieven, paklijsten, douaneformulieren.
De informatie die erin staat is cruciaal, maar komt er niet vanzelf uit. Dus wordt er gelezen, overgetypt en gecontroleerd. Handmatig, elke keer opnieuw.
Dit werk is niet ingewikkeld. Maar het kost veel tijd, schaalt slecht en de kans op fouten is groter dan je wilt. Zeker op momenten waarop precisie juist belangrijk is.
Een AI-oplossing die PDF-documenten automatisch uitleest, relevante gegevens extraheert en klaarmaakt voor verdere verwerking kan het verschil maken. In dit blog leg ik uit hoe zo’n oplossing werkt, welke technische keuzes daarbij komen kijken en wat je er in de praktijk van kunt verwachten.

Wat is Intelligent Document Processing?
Intelligent Document Processing, of IDP, is geen nieuwe technologie. Traditionele IDP-systemen werken met OCR (optische tekenherkenning) en vaste sjablonen. Ze herkennen tekst op vooraf bepaalde posities in een document. Voor hoge volumes met een vaste opmaak werkt dat prima.
Maar zodra de opmaak varieert, een leverancier zijn factuurlayout aanpast of documenten uit verschillende landen binnenkomen, wordt het lastiger.
Wat onze oplossing anders maakt, is de combinatie van IDP met een Large Language Model (LLM), de technologie achter tools als ChatGPT. Een LLM begrijpt context. Het maakt niet uit waar een bedrag op de pagina staat, in welke taal een document is opgesteld of hoe de structuur per jaar verschilt. De AI leest het document zoals een ervaren medewerker dat zou doen en haalt er de juiste informatie uit.
Die flexibiliteit vraagt wel om goede instructies. De kwaliteit van de output hangt af van hoe duidelijk je aangeeft welke velden je wilt extraheren, wat de verwachte formaten zijn en wanneer iets gecontroleerd moet worden door een mens. Die voorbereiding is het echte werk. De technologie voert het daarna betrouwbaar uit.
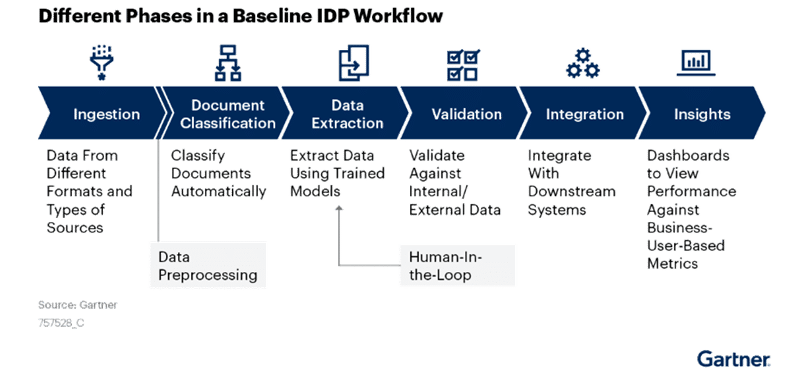
Onderstaand schema laat een algemene IDP-workflow zien, zoals beschreven door Gartner:
Hoe we het hebben gebouwd
Voor de infrastructuur kozen we voor Microsoft Azure. De belangrijkste reden is praktisch: alle data blijft op servers in West-Europa. Voor organisaties met strenge privacy- of compliancevereisten is dat belangrijk.
Daarnaast biedt Azure alles wat je nodig hebt op één plek: opslag, AI-verwerking, database en de logica die alles verbindt.
De workflow zelf is eenvoudig. Een gebruiker uploadt een PDF. De AI ontvangt het document, samen met instructies over welke informatie nodig is. Het model extraheert de gevraagde waarden en zet deze om naar JSON, een formaat dat zowel door systemen als door mensen goed leesbaar is.
Daarna controleert het systeem automatisch of de waarden kloppen en binnen verwachte grenzen vallen. Wat correct is, gaat direct door naar de database. Wat twijfelachtig is, legt het systeem voor aan een medewerker, die het met een snelle check goedkeurt of corrigeert.
Wat de nauwkeurigheid verder verhoogt, is dat het model na de eerste extractie een reflection pass uitvoert. Het krijgt zijn eigen output terug als input en beoordeelt die opnieuw, veld voor veld, om inconsistenties en gemiste waarden op te sporen en te corrigeren. Dat klinkt als een detail, maar het maakt in de praktijk echt verschil, vooral bij complexe of onregelmatig opgemaakte documenten.
De resultaten
We hebben de oplossing gevalideerd in een pilottest met zeven documenten in vier talen: Engels, Nederlands, Duits en Frans. Met zeven documenten trek je geen statistisch harde conclusies, en dat is ook niet de bedoeling van zo’n pilot. Wat je wel kunt vaststellen: werkt de aanpak, zijn de resultaten bruikbaar en waar zit de frictie? Op alle drie de vragen was het antwoord positief.
Hoe accuraat het model in productie presteert, verschilt per situatie. Dat hangt af van de kwaliteit van de documenten, de complexiteit van de te extraheren velden en hoe goed de instructies zijn afgestemd op het model. Dat afstemmen, de configuratie van de oplossing op jouw specifieke documenttypen, is dan ook een vast onderdeel van hoe we dit soort trajecten aanpakken.
Ter illustratie van wat het model aankan: we testten ook documenten waarin velden ontbraken, bedragen in ongebruikelijke valutanotaties stonden of tabellen over meerdere pagina’s liepen. In de meeste gevallen gaf het model correct aan dat een waarde ontbrak of twijfelachtig was, in plaats van iets te verzinnen. Dat gedrag is minstens zo waardevol als een hoge score op de makkelijke gevallen.
We testten ook meerdere LLM-modellen naast elkaar, van slimmer tot compacter en volledig binnen de EU verwerkend. Afhankelijk van wat een organisatie belangrijk vindt, is er een passende keuze te maken.
Wat dit betekent in de praktijk
Wat betekent dit nu eigenlijk voor een organisatie? Het betekent dat medewerkers een groot deel van het handmatige leeswerk niet meer hoeven te doen. Documenten komen binnen, de workflow draait en de data staat klaar in de database. Alleen de twijfelgevallen worden voorgelegd aan een medewerker voor een snelle check.
Dat heeft een paar praktische voordelen. Het werk schaalt mee met het volume: tien documenten of duizend, de workflow doet hetzelfde. Je bespaart veel tijd en de kans op typefouten of gemiste waarden neemt flink af.
Wat ook helpt: de oplossing is niet gebonden aan één documenttype of één sector. Zolang je kunt beschrijven welke informatie je uit een document wilt halen, kan de AI daarmee aan de slag. Dat maakt het toepasbaar op veel meer situaties dan alleen het voorbeeld waarmee we zijn begonnen.
Wil je weten wat dit voor jouw organisatie kan betekenen?
Documentverwerking is een van die processen waar je pas echt bij stilstaat als het misgaat of als het te veel tijd kost. Een geautomatiseerde oplossing is dan geen luxe, maar een logische stap.
Bij E-mergo bouwen we dit soort AI-oplossingen als maatwerk, afgestemd op jouw documenttypen, systemen en compliancevereisten. Een eerste gesprek is meestal genoeg om te bepalen of er iets zinvols te bouwen valt en hoe een traject er globaal uit kan zien.
Blijf op de hoogte
Wil je geen blog missen? Schrijf je dan in voor onze nieuwsbrief. Zo ontvang je elke maand alle nieuwste content direct in je mailbox. Je kunt je inschrijven via de knop hieronder.

Geschreven door Tom de Bruijne
BI Consultant







