Jouw eerste dataproduct bouwen in Qlik

In deel 1 van deze serie bespraken we het concept van dataproducten, de Data Mesh-filosofie en wat je moet overwegen voordat je aan de slag gaat. In dit blog duiken we de Qlik-omgeving zelf in. Ik neem je mee door de opbouw van een Qlik Dataproduct en laat stap voor stap zien hoe je er een aanmaakt en welke beslissingen je onderweg kunt nemen.
Of je nu een Qlik-ontwikkelaar bent die al jarenlang QVD-lagen bouwt of nog niet zo lang met het platform werkt: aan het einde van dit blog heb je een concreet idee van hoe het werken met Dataproducten in Qlik er in de praktijk uitziet.
Een feature voor elke Qlik Cloud-gebruiker, met een paar extra’s voor Talend QDI
Zoals vermeld in het eerste blog lanceerde Qlik dataproduct-functionaliteit al enige tijd geleden als onderdeel van het Talend Cloud Data Integration (QDI) aanbod. Het grote nieuws is dat Dataproducten nu ook beschikbaar zijn voor Qlik Cloud Analytics. Dat betekent dat je jouw QVDs en andere data-assets direct in de Analytics-omgeving waar je al mee werkt kunt bundelen tot een volwaardig dataproduct, zonder QDI-licentie.
Voorheen betekende het toepassen van dataproduct-principes op je QVD-laag dat je naar een ander deel van het platform moest overstappen. Nu hebben Qlik Analytics-gebruikers toegang tot dezelfde governance-mogelijkheden: gestructureerd eigenaarschap, vindbaarheid, lineage en kwaliteitsmonitoring. Kortom: als je een Qlik Analytics-omgeving hebt en een redelijk goed gestructureerde QVD-laag, ben je al een heel eind op weg. De dataproduct-functionaliteit biedt je de structuur om te formaliseren wat je al aan het doen bent.
Waar een Qlik Dataproduct uit bestaat
Voordat je iets aanmaakt, helpt het te begrijpen waaruit een Qlik Dataproduct eigenlijk bestaat. De kern van een dataproduct wordt gevormd door datasets: je QVDs, of ruimer gezien alle geregistreerde data-assets in de Qlik Catalog, gegroepeerd in een samenhangende, domeinspecifieke collectie. Maar rondom die datasets zitten meerdere lagen van functionaliteit die van een simpele bestandsgroepering iets werkelijk nuttigs maken.
Elk dataproduct heeft een eigen documentatiepagina waarop je het doel, de inhoud en de context beschrijft die afnemers nodig hebben. Qlik biedt een GenAI-ondersteunde documentatiefunctie die een eerste versie kan opstellen op basis van je datasetnamen en metadata. Een goed startpunt, al zul je het altijd willen nalezen en personaliseren. Naast de documentatie staat eigenaarschapsinformatie centraal: wie is er eigenaar van het product en wie moet je bereiken als er iets niet klopt? Dit is geen decoratieve metadata: het is een cruciaal governance-onderdeel dat vaak wordt onderschat.
Qlik houdt ook automatisch lineage bij voor de datasets in je product: waar de data vandaan komt, welke transformaties die heeft doorlopen en van welke apps of andere downstream assets die hiervan afhankelijk zijn. Die lineage is gevisualiseerd en direct beschikbaar voor afnemers vanuit de dataproduct-interface. Tot slot draagt elke dataset een Trust Score: Qlik’s datakwaliteit framework dat afnemers een indruk geeft van de algehele kwaliteit van de data. Hoe dat precies werkt, bespreken we uitgebreid in deel 3 van deze blogserie. Als alles op orde is, kan het product worden gepubliceerd op de Data Marketplace: de self-service discovery-laag waar zakelijke gebruikers dataproducten kunnen bekijken en gebruiken. Meer daarover in deel 4.
Een dataproduct aanmaken, stap voor stap
Nu wordt het praktisch. Zo maak je een dataproduct aan in Qlik Cloud Analytics.
Stap 1: Zorg dat je datasets geregistreerd zijn
Voordat je een dataproduct kunt aanmaken, moeten je QVDs of andere data-assets geregistreerd zijn in de Qlik Catalog. In Qlik Cloud kun je ze direct vanuit de catalog-interface registreren door Qlik naar de relevante space en verbinding te wijzen. Eenmaal geregistreerd zijn ze beschikbaar voor profilering, kwaliteitsmonitoring en opname in dataproducten. Als je Qlik Talend Data Integration gebruikt om data te landen en te transformeren, staan je datasets al in de catalog als onderdeel van die pipeline.
Stap 2: Navigeer naar Dataproducten
Open vanuit het Qlik Cloud-startmenu Dataproducten. Dit is je thuisbasis voor het aanmaken en beheren van dataproducten. Je ziet een overzicht van bestaande producten en een optie om een nieuw product aan te maken.
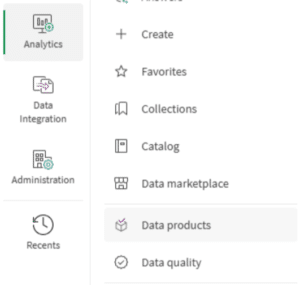
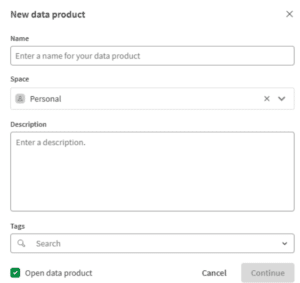
Stap 3: Maak het dataproduct aan
Klik op het aanmaken van een nieuw dataproduct. Je wordt gevraagd om een naam, een beschrijving en een space. Kies voor de naam iets beschrijvends en domeinspecifieks. ‘Finance’ is te breed; ‘Financiële Resultaten & Actuals’ is beter. Sla de beschrijving niet over. Zelfs twee zinnen helpen afnemers al te bepalen of dit product is wat ze zoeken. De space die je kiest bepaalt de toegang: wie het product kan zien en gebruiken wordt bepaald door de rechten op die space.
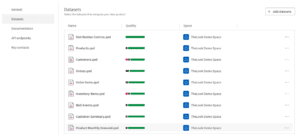
Stap 4: Voeg datasets toe
Nu voeg je de datasets toe die bij dit product horen. Dit is waar de belangrijkste ontwerpbeslissing valt, en daar besteden we in de volgende sectie meer aandacht aan. De korte versie: neem datasets op die logisch bij hetzelfde businessdomein horen en die een afnemer doorgaans samen nodig heeft. Een dataproduct dat elke dataset van je organisatie bevat is geen product, dat is een data dump.
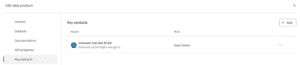
Stap 5: Stel eigenaarschap en documentatie in
Wijs een eigenaar toe en voeg relevante contactinformatie toe. Qlik laat je vrij invulbare roltitels toevoegen naast de naam van de betreffende persoon, waardoor je de flexibiliteit hebt om de daadwerkelijke governance-structuur van jouw organisatie te weerspiegelen. Enkele rollen die het overwegen waard zijn:
- Dataproduct Owner: verantwoordelijk voor de bedrijfswaarde en de levenscyclus van het product. Dit is de persoon die bepaalt wat er in het product zit en het relevant houdt. In Qlik-termen zal deze persoon doorgaans ook de platformrol Dataproduct Manager hebben.
- Data Owner: de senior bedrijfsstakeholder met eindverantwoordelijkheid voor het domein dat dit product vertegenwoordigt. Vaak een afdelingshoofd of vergelijkbaar. Niet per se een dagelijkse operationele rol, maar wel het juiste escalatiepunt voor toegangs- en beleidsbeslissingen.
- Data Steward: de operationele bewaker van de data. Bewaakt de kwaliteit, onderhoudt definities en documentatie, en onderzoekt afwijkingen. Dit is de persoon die afnemers moeten bellen als er iets niet klopt.
- Technisch contactpersoon: de data engineer of ontwikkelaar die de onderliggende pipelines en QVDs heeft gebouwd en onderhoudt. Houd dit gescheiden van de bovenstaande business-rollen; afnemers verdienen het te weten wie de boel repareert als er iets stukgaat.
Je hoeft niet alle vier de rollen voor elk dataproduct in te vullen, zeker niet bij het begin. Maar het hebben van minimaal een Dataproduct Owner en een Technisch contactpersoon geeft afnemers twee duidelijke aanspreekpunten en draagt sterk bij aan het vertrouwen in het product.
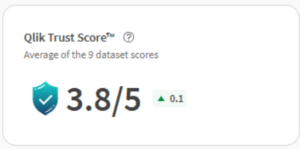
Stap 6: Controleer de Trust Score
Kijk voor publicatie naar de kwaliteitsmetrieken van je datasets. Als een of meerdere scores laag zijn, is het de moeite waard om de oorzaak te onderzoeken voordat je het product blootstelt aan afnemers. Deel 3 van deze serie gaat hier uitgebreid op in.
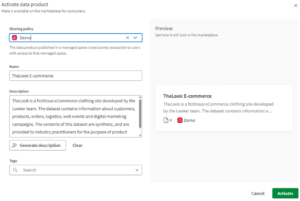
Stap 7: Activeer en publiceer
Als je tevreden bent, activeer je het product en publiceer je het op de Data Marketplace. Tijdens de activering kies je in welke managed space de gepubliceerde kopie verschijnt. Alle gebruikers met de juiste toegang tot die space kunnen het dataproduct vervolgens ontdekken en gebruiken.
De beslissingen die er het meest toe doen
Een dataproduct aanmaken is het makkelijke deel. Het goed structureren vraagt meer nadenken. Hier zijn een aantal tips en overwegingen voor effectievere dataproducten.
Welke scope is zinvol?
De beste dataproducten zijn gericht op een businessdomein, niet op een technisch systeem. ‘Salesdata uit CRM’ is een technische beschrijving; ‘Klant- & Opportunityintelligentie’ is een domeingerichte. Domeingerichte producten worden eerder hergebruikt voor meerdere use cases, omdat ze zijn gedefinieerd rondom een bedrijfsconcept in plaats van een databron. Een nuttige vraag om te stellen: hebben afnemers van dit product doorgaans alle datasets samen nodig, of zijn sommige datasets onwaarschijnlijk naast elkaar te gebruiken? Als dat laatste het geval is, horen die datasets misschien in een apart product thuis.
Aan de andere kant: splits ook niet te agressief. Als afnemers consequent datasets uit twee verondersteld aparte producten moeten combineren om één vraag te beantwoorden, horen die datasets waarschijnlijk bij elkaar.
Welke rollen wijs je toe?
Qlik Dataproducten werken binnen het bestaande rolgebaseerde toegangsmodel van Qlik. De twee sleutelrollen zijn de Dataproduct Manager en de Can Consume-rol. De Dataproduct Manager kan dataproducten aanmaken en beheren. Dit is de persoon die verantwoordelijk is voor de levenscyclus van het product: bepaalt wat erin gaat, onderhoudt de documentatie en is aanspreekbaar op kwaliteit. Zie het als een product owner-rol in softwareontwikkelingszin. De Can Consume-rol geeft gebruikers de mogelijkheid om het dataproduct te ontdekken en te gebruiken: door de marketplace te bladeren, kwaliteitsmetrieken te bekijken en direct analytics-apps vanuit het product te maken. Het doordacht toewijzen van deze rollen is wat het verschil maakt tussen een dataproduct dat wordt gebruikt en een dat digitaal stof vergaart.
Hoe zit het met beveiliging?
Het publiceren van een dataproduct omzeilt Qlik’s toegangscontroles niet. Toegang tot de onderliggende data wordt nog altijd bepaald door de rechten op de datasets en spaces. Het dataproduct is een discovery- en governance-laag. Het helpt gebruikers de data te vinden en te begrijpen, maar het verandert niets aan wat ze mogen zien. Dit is een belangrijk punt om duidelijk te communiceren aan beveiligingsbewuste stakeholders: een dataproduct is geen achterdeur.
Volgende keer: je data betrouwbaar maken
Nu je weet hoe je een dataproduct bouwt in Qlik, is de logische volgende vraag: hoe zorg je ervoor dat de data erin ook écht betrouwbaar is? Een goed gestructureerd product gevuld met onnauwkeurige of verouderde data is aantoonbaar erger dan helemaal geen product, omdat het een vals gevoel van vertrouwen creëert.
In deel 3 van deze serie gaan we diep in op datakwaliteit: hoe de Qlik Trust Score werkt, hoe je die afstelt en vernieuwt, hoe je je eigen kwaliteitsregels definieert en hoe Qlik’s AI je kan helpen kwaliteitsproblemen te ontdekken die je nog niet eens wist dat je had. Tot dan!
Contact
Benieuwd hoe dataproducten in Qlik jouw organisatie kunnen helpen om meer waarde uit data te halen? Bij E-mergo ondersteunen we organisaties bij het opzetten van dataproducten, het versterken van data governance en het optimaal inzetten van het Qlik-platform.
Wil je sparren over jouw situatie of eens praktisch kijken wat er mogelijk is? Neem gerust contact met ons op. We denken graag met je mee.
Blijf op de hoogte
Wil je geen blog missen? Schrijf je dan in voor onze nieuwsbrief. Zo ontvang je elke maand alle nieuwste content direct in je mailbox. Je kunt je inschrijven via de knop hieronder.

Geschreven door Lennaert van den Brink
Cluster Manager/Senior BI Consultant







