Aan de slag met Qlik Predict: van model naar actie

De toekomst voorspellen, wie wil dat nou niet? Met Qlik Predict (de nieuwe benaming voor AutoML) kun je eenvoudig voorspelmodellen creëren op basis van jouw data. Qlik Predict automatiseert een groot deel van dit proces voor je. In de vorige blogs hebben we uitgelegd hoe je jouw data voorbereidt met feature engineering en hoe je het beste model selecteert. In dit derde deel laten we zien hoe je het getrainde model daadwerkelijk inzet in je organisatie: het operationaliseren van je model.
Van experiment naar inzetbaar model
Zodra je tevreden bent met het resultaat van je experiment, kun je het model deployen. Dit betekent dat je het model beschikbaar maakt om voorspellingen mee te genereren. In Qlik gebeurt dit via een zogenaamde ‘ML deployment’. Je kunt een model deployen naar een nieuwe of bestaande deployment.
Zodra je één of meer modellen hebt toegevoegd aan een deployment moet ten minste één van de modellen worden goedgekeurd om ook voorspellingen te kunnen genereren. Heb je meerdere modellen, dan kies je één van de modellen als “default” model, voor de overige modellen kun je ‘aliassen’ aanmaken. Deze aliassen kun je gebruiken om het juiste model aan te spreken.
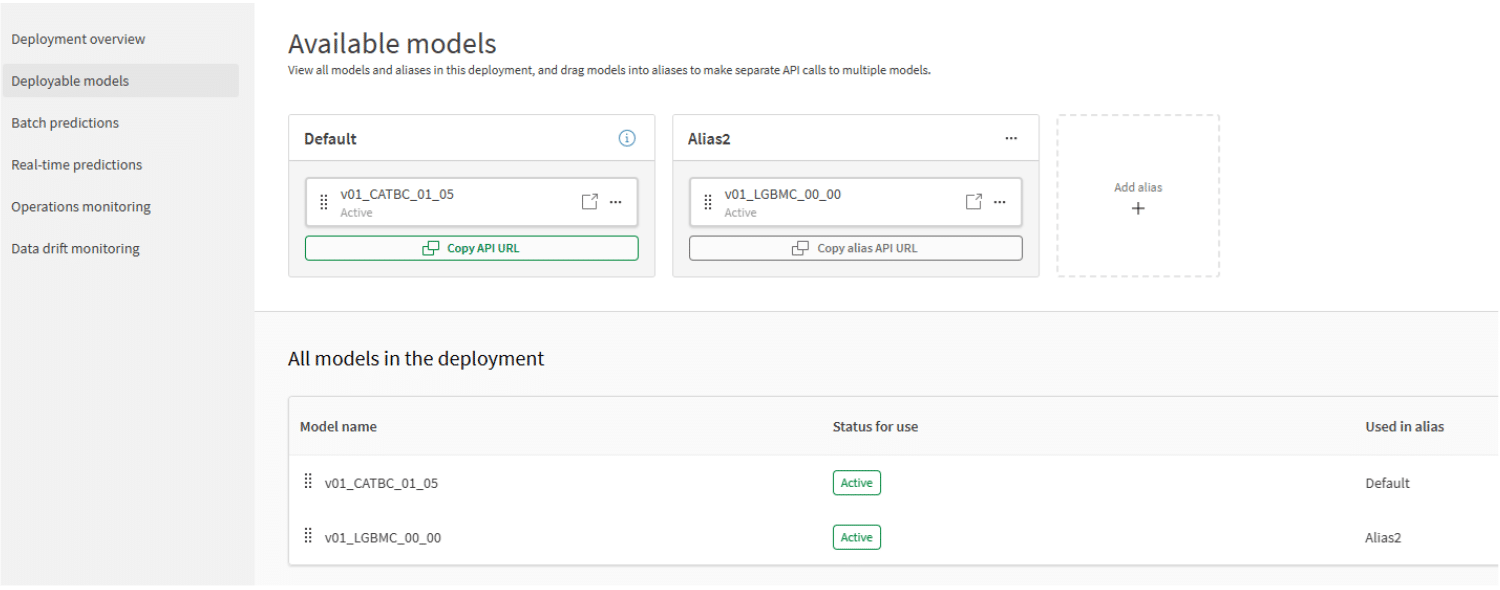 Figuur 1: Inzetbare modellen (klik op het figuur voor een grotere weergave).
Figuur 1: Inzetbare modellen (klik op het figuur voor een grotere weergave).
Voorspellingen maken: handmatig, gepland of real-time
Als het model eenmaal is goedgekeurd, kun je het gebruiken om voorspellingen mee te genereren. Dit kan op drie manieren:
- Batch voorspelling: via de interface van de deployment kies je een bestaande dataset als input voor de voorspelling. Qlik controleert of de juiste features aanwezig zijn op basis van kolomnamen. Vervolgens kies je het model dat je wilt gebruiken, geef je de output dataset, de plek waar deze wordt opgeslagen,naam en kies je het format waarin deze wordt opgeslagen (qvd, parquet of CSV). Je kunt er vervolgens nog voor kiezen of deze export eenmalig is of periodiek wordt uitgevoerd.
- Real-time API: Voor elke alias in een deployment wordt een URL gegenereerd. Dit is een REST API endpoint waar je door middel van een POST call een voorspelling kunt genereren. Deze methode is ideaal wanneer je jouw voorspelmodel wilt intergreren met een andere applicatie buiten het Qlik platform.
Om een voorspelling te genereren geef je een “Authorization” header mee met een geldigde API key en in de body de juiste kolomnamen die overeen komen met de features van het model. Een voorbeeld van een body voor een dergelijke aanroep zie je hieronder:
{
"rows": [["feature1waarde", "feature2waarde"]],
"schema": [{"name": "feature1"},{"name": "feature2"}]
} - Analytic connection: Als je live voorspellingen in een dashboard van Qlik wilt intergreren kan je gebruik maken van een zogeheten “Analytic connection”. Je maakt de connectie op dezelfde manier aan als een dataconnectie in het laadscript. Als je de connectie hebt aangemaakt kan je in een expressie met behulp van Serverside Extension (SSE) syntax een voorspelling genereren. Een voorbeeld expressie ziet er als volgt uit:
=endpoints.ScriptEvalEx(
'SSSSN',
'{"RequestType":"endpoint", "endpoint":{
"connectionname":"MyConnection",
"column":"MyTargetColumn"}}',
[Feature1],
[Feature2],
[Feature3],
[Feature4],
[SyntheticDimension] as [Feature5]
)
De aanroep begint altijd met een aanroep van endpoints.scriptEvalEx. Vervolgens is de eerste parameter een string die bestaat uit letters S (String) en N (Numeric). Dit geeft aan welk type data in elk van de features wordt verwacht. Vervolgens geef je de naam van de analytic connectie mee en vertel je de naam van de kolom die je wil voorspellen. Tot slot geef je de verschillende waarden mee die je wil gebruiken voor de simulatie. Door kolommen uit je datamodel te kiezen maak je de voorspelling dynamisch, zodat deze reageert op de selecties van de gebruiker.
Van voorspelling naar actie
Nu we weten hoe je een voorspelling kan genereren is het tijd om deze onderdeel te maken van je dashboards. Heb je een batch voorspelling gemaakt, dan heb je een nieuwe dataset gekregen die je net als elke andere dataset in je model kan laden. In de dataset zit een sleutel naar je datamodel en afhankelijk van het type voorspelmodel een aantal kolommen met de voorspelling. Heb je bijvoorbeeld een binaire of multiclass classificatie gebruikt, dan zal je een kolom hebben per label met daarin de kans die het model geeft dat dit label de juiste is. Stel je hebt een binair classificatiemodel gemaakt dat voorspelt of een klant wel of niet zijn abonnement behoudt, kan je met deze informatie een KPI object maken met het aantal klanten die hoog, midden of laag risico vertonen om hun abonnement op te zeggen.
De volgende stap is om je gebruikers inzicht te geven in waarom een bepaalde voorspelling wordt gedaan door het model. Daarvoor kan je de zogeheten SHAP values gebruiken. Deze SHAP values kan je mee laten genereren met een voorspelling. Je krijgt dan per feature in jouw voorspelmodel voor elke voorspelde regel een waarde tussen -1 en 1. Een positieve waarde betekent dat de feature een positieve invloed heeft gehad op de voorspelde uitkomst en een negatieve waarde betekent juist een negatieve invloed. Hoe hoger (of bij negatieve waarde hoe lager) de waarde, hoe groter de invloed.
In figuur 2 zie je een voorbeeld van hoe de voorspellingen en SHAP values kunnen worden gebruikt in een dashboard. In de linker staafdiagram zie je per fiets een voorspelling van de kans dat deze fiets te laat geleverd gaat worden. De staafdiagram aan de rechter kant toont per feature de SHAP values. Zoals je kunt zien hebben de kolommen “Customer location”, “Transport Company” en “Model Configuration” de grootste bijdragen aan het te laat zijn van de levering, het “Planned Delivery Season” heeft dan juist weer een positieve invloed op het op tijd komen van de levering. Selecteert de gebruiker een specifieke levering dan passen de SHAP values aan zodat de gebruiker kan zien welke specifieke factoren op die levering van grootste invloed zijn.
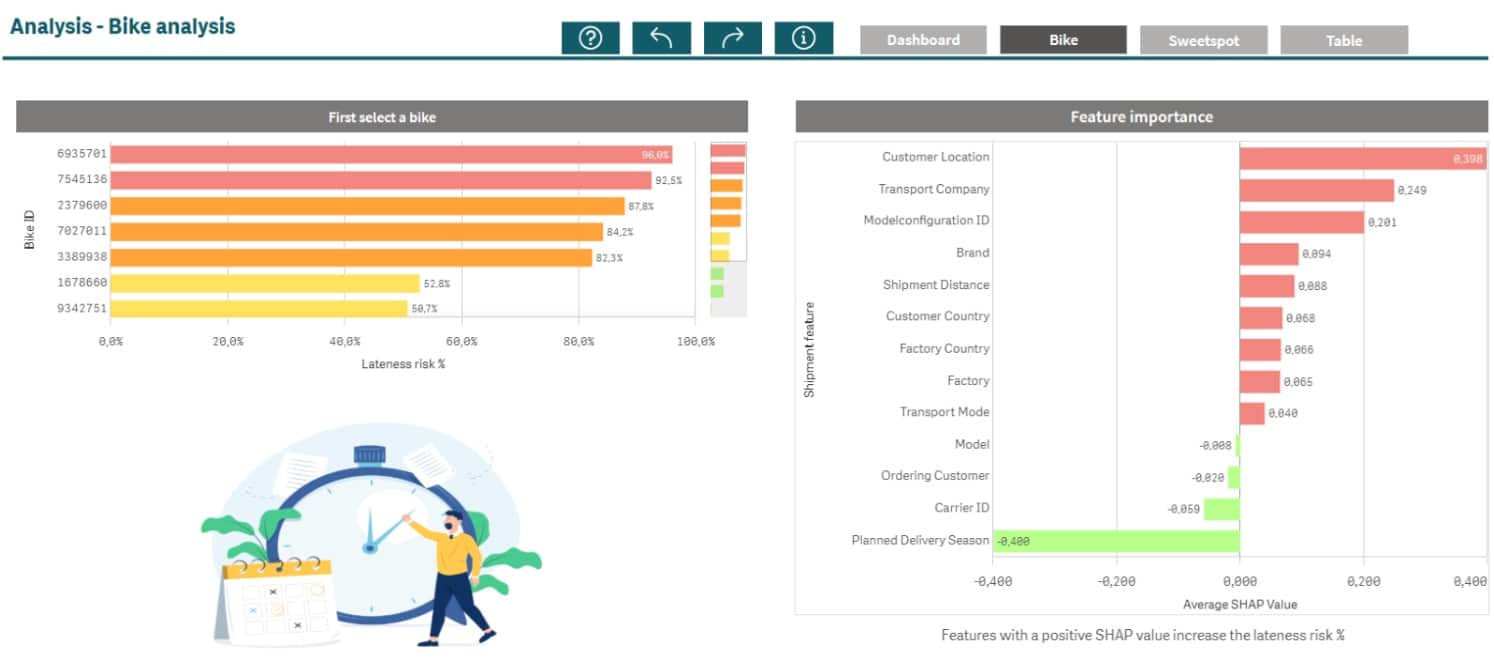
Figuur 2: Voorspellingen en SHAP values (klik op het figuur voor een grotere weergave).
What-if scenario’s en sweetspot analyses
Door gebruik te maken van de analytic connection kan je de gebruiker in staat stellen nog geavanceerdere analyses uit te voeren. Zo kun je bijvoorbeeld de gebruiker in de gelegenheid stellen om input waardes te kiezen via een variabele input box, waarna een nieuwe voorspelling gegenereerd wordt. Op die manier kan je bijvoorbeeld kijken wat het effect is van het aanpassen van een leverancier op de kans dat de levering op tijd gaat komen.
Nog krachtiger is het om een zogeheten sweetspot analyse uit te voeren. Bij een sweetspot analyse laat je een grote hoeveelheid combinaties van feature waarden tegelijk simuleren en plot je die bijvoorbeeld in een scatterplot. In figuur 3 zie je de kans op te late leveringen per mogelijke leverancier worden uitgezet tegen de kosten die zijn verbonden aan het inzetten van die leverancier. Op deze manier kan je in een oogopslag zien welke leverancier voor deze specifieke levering de juiste combinatie van prijs/kwaliteit biedt. Als je dan vervolgens de gebruiker de mogelijkheid geeft om die keuze te bekrachtigen middels application automation flow is de hele cirkel rond.
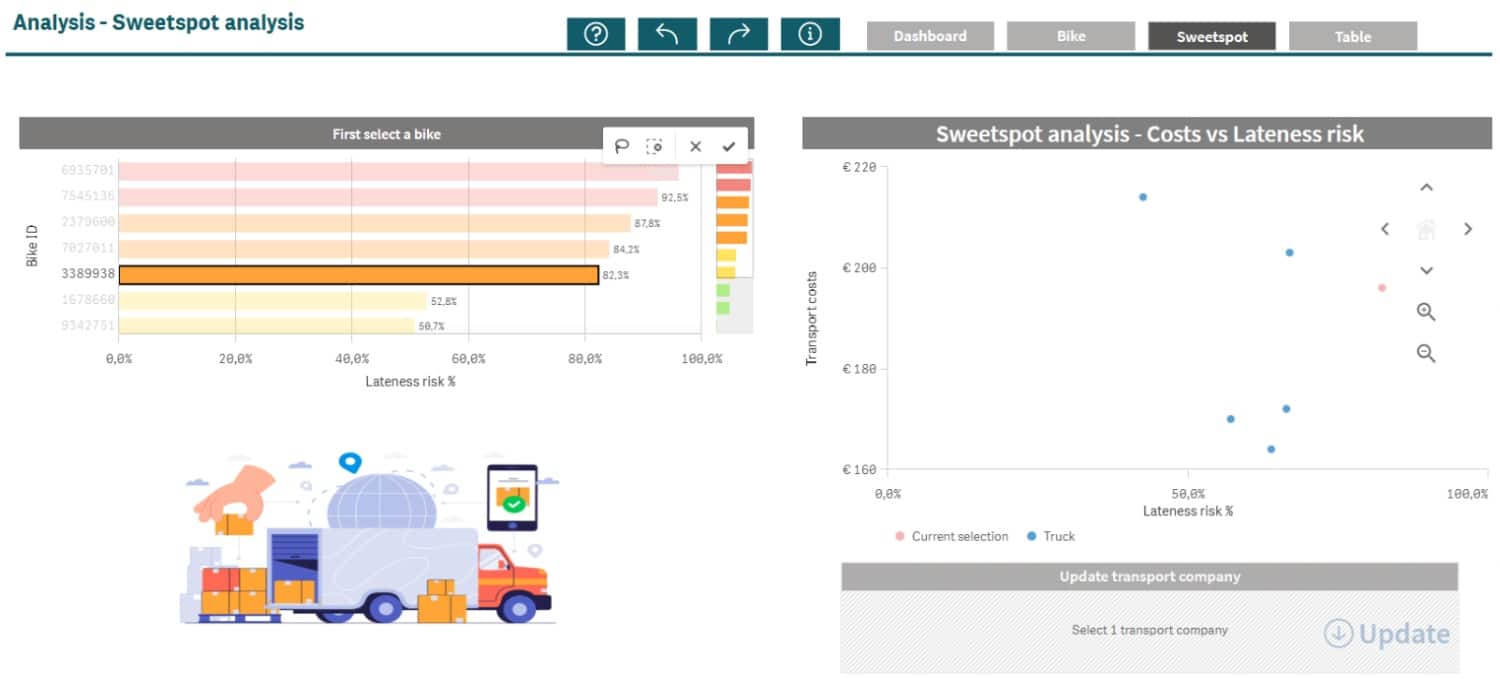 Figuur 3: Sweetspot Analyse (klik op het figuur voor een grotere weergave).
Figuur 3: Sweetspot Analyse (klik op het figuur voor een grotere weergave).
Houd je model gezond: monitoring en vervanging
Een model is niet statisch. De wereld verandert, en daarmee ook je data. Stel bijvoorbeeld dat ik in de jaren 90 een voorspelmodel had getraind om te voorspellen hoe veel benzine mijn tankstation maandelijks verkoopt. Dat model zal enige tijd prima voorspellingen hebben afgegeven, maar met de komst van elektrische auto’s en het zuiniger worden van moderne motoren zal het model steeds minder nauwkeurige voorspellingen doen. Qlik Predict monitort automatisch of de data waarop voorspellingen worden gedaan nog lijkt op de data waarop het model is getraind. Dit heet data drift monitoring. Qlik gebruikt hiervoor een meetwaarde genaamd Population Stability Index (PSI). Een PSI onder de 0.1 betekent dat alles stabiel is. Tussen 0.1 en 0.25 is er lichte drift, en boven de 0.25 is het tijd om je model opnieuw te trainen of te vervangen.
Naast model drift is het ook belangrijk om te monitoren op foutmeldingen bij het voorspellen. Errors kunnen bijvoorbeeld ontstaan omdat er features ontbreken of juist ineens waarden bevatten die tijdens het trainen nog niet zijn gezien. Stel bijvoorbeeld ik had als input de feature “kleur” en in mijn trainingsdataset kwamen de kleuren “rood”, “groen” en “blauw” voor. Als ik dan een nieuwe voorspelling probeer te genereren en ik geef als kleur mee “oranje”, dan zal het voorspelmodel niet weten wat te doen en genereert het een foutmelding. Als je een batchvoorspelling doet kan je ervoor kiezen om naast de voorspellingen en SHAP waardes ook een Error tabel weg te schrijven. Dit kan helpen om in de gaten te houden of er fouten optreden en waar je actie op moet ondernemen.
Moet je model vervangen worden? Geen probleem. Dankzij het gebruik van model-aliases kun je een nieuw model koppelen aan dezelfde deployment zonder dat je je dashboards of API-calls hoeft aan te passen.
Tot slot
Het trainen van een voorspelmodel is slechts het begin. De echte waarde ontstaat pas als je het model inzet in je processen, dashboards en beslissingen. Met Qlik Predict is het operationaliseren van een model eenvoudig, schaalbaar en goed te beheren. Met het integreren van jouw voorspelmodel in je dashboards kun je echt acties gaan ondernemen op basis van de inzichten die je krijgt. En dat is precies hoe je de maximale waarde uit jouw voorspellingen kunt halen.
Blijf op de hoogte
Wil je geen blog missen? Schrijf je dan in voor onze nieuwsbrief. Zo ontvang je elke maand alle nieuwste content direct in je mailbox. Je kunt je inschrijven via de knop hieronder.

Geschreven door Lennaert van den Brink
Cluster Manager/Senior BI Consultant







