‘Data First’

‘Data First’; het klinkt misschien als een statement uit een verkiezingscampagne maar dit was het thema van de 5e editie van de Data Warehousing & Business Intelligence Summit in Utrecht. Het event vond de afgelopen 2 dagen plaats en behandelde verschillende trending topics op het gebied van data warehousing en business intelligence zoals GDPR, Data Lakes, Data Science en Dark Data. E-mergo was samen met TimeXtender sponsor van de summit. Majken Sander, Solution Architect bij TimeXtender, verzorgde namens E-mergo en TimeXtender dinsdag een interessante sessie over de toekomst van business intelligence architectuur. Lees in dit blog meer over de summit en ontdek of jouw BI architectuur klaar is voor de toekomst.
‘Data First’
Het ‘Data First’ thema wordt tijdens de eerste dag van het seminar al snel duidelijk wanneer er wordt gesproken over de verschillende toegangswegen die er nu zijn voor data consumenten, zowel intern als extern. Het gebruik en de verzameling van data is drastisch aan het veranderen en aan het toenemen. Data wordt nu breder en intensiever gebruikt en steeds meer personen willen er toegang toe hebben. Dit alles zet druk op de architectuur en roept vragen op over hoe lang bestaande constructies overeind zullen blijven.
Kom van je data eiland af

De toenemende behoefte vanuit de business om met data aan de slag te gaan zorgt ervoor dat afdelingen verschillende ‘data delivery systems’ gaan implementeren. Denk hierbij aan het data warehouse zoals we die kennen maar ook aan data lakes, data marketplaces, data services en data streaming(real time data). Al deze systemen verzamelen en behandelen data uit je bron systemen op een andere manier en dat terwijl zij allemaal te maken krijgen met gedeelde specificaties en vaak ook gedeelde gebruikers. Denk hierbij aan het ETL (Extract, Transform, Load) proces en het vaststellen van definities. Hierdoor loop je het risico op data eilandjes met inconsistente resultaten. Het is ideaal is daarom om 1 universele architectuur te creëren vanwaar alle wensen voldaan kunnen worden. Op deze manier beschik je over consistente data en voorkom je dat werk dubbel uitgevoerd hoeft te worden. Maar hoe maak je dit ideale beeld een realiteit?
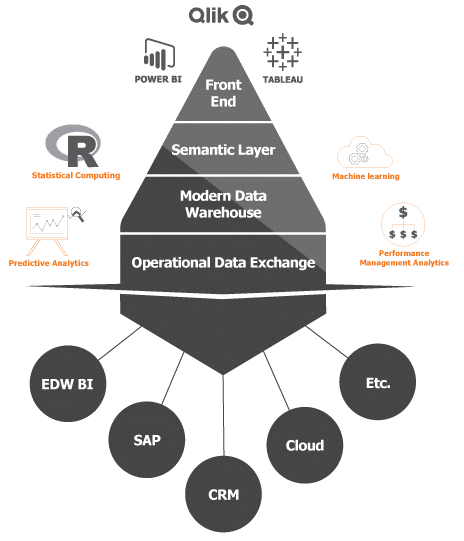
Creëer één centrale Data Hub
Één universele architectuur kun je zien als een soort hub van waar je business logica kunt beheren om vervolgens de juiste gebruikers op de juiste plek toegang te kunnen geven. Gebruikers hebben namelijk verschillende behoeftes. Een data scientist zou dichter op de bron willen zitten terwijl management toegang wil tot berekende gegevens en key KPI’s. Om deze gebruikers toegang te geven op verschillende niveau’s zonder consistentie te verliezen heb je een architectuur nodig die mee kan groeien en waarin je eenvoudig meerdere bronnen kunt verbinden. Dit is precies wat de Discovery Hub® van TimeXtender doet. Hiermee kun je meerdere datavisualisatie tools zoals Qlik eenvoudig laten draaien op dezelfde berekeningen en definities die gemaakt worden in de semantic layer. Zo weet je zeker dat de hele organisatie met dezelfde gegevens werkt én dat zij toegang krijgen op het benodigde niveau. Data scientists kunnen met de Discovery Hub® bijvoorbeeld data halen uit de operational data exchange of vanuit hier bewerken met statische of voorspellende tools zoals R of Python.
Is jouw BI architectuur klaar voor de wensen van morgen?
Het ‘Data First’ thema werd ook duidelijk in de presentatie van Majken Sander, Solution Architect bij TimeXtender, wanneer zij de case van Nedap beschreef tijdens haar presentatie. Nedap, een multinational organisatie gericht op identificatie en security oplossingen, beschikte over verschillende bronsystemen en meerdere datavisualisatie tools (front-ends). Nedap werkte hierdoor met verschillende data transformaties en berekeningen in de landen waar zij actief zijn en visualiseerde deze data ook met verschillende analyse tools. Sommige van deze tools waren direct op de databronnen aangesloten terwijl andere werkten met data extracties.
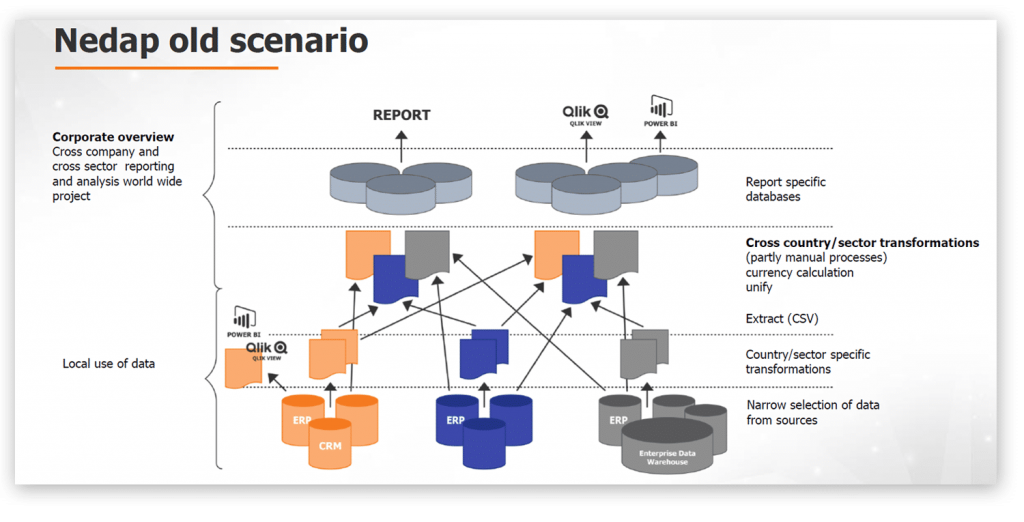
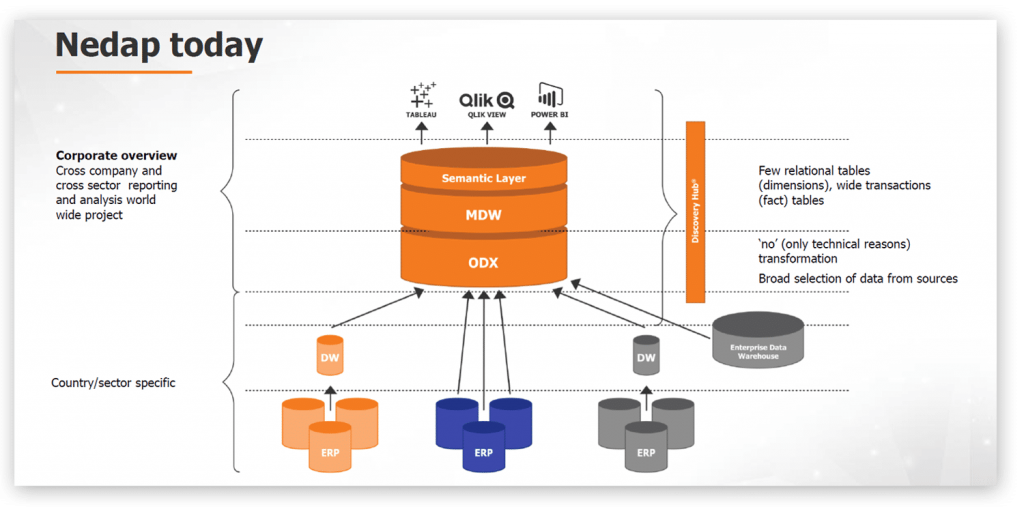
Deze architectuur werkte op zich prima voor specifieke landen maar maakte het creëren van een totaal overzicht voor de organisatie heel tijdrovend en moeilijk. Daarnaast bestond de kans dat data verouderd was doordat data uit het ERP geëxporteerd moest worden naar een CSV bestand voordat het in QlikView geladen kon worden. Bovendien was het toevoegen of veranderen van databronnen erg lastig. Door de implementatie van de Discovery Hub® beschikt Nedap sneller over accurate data die zij eenvoudig in QlikView, Excel of elke andere data analyse tool kunnen visualiseren en analyseren. Data is in de hub altijd up-to-date en juist en geeft Nedap de vrijheid hierdoor vrijheid om met verschillende front end tools te kunnen werken. Veranderingen in bronsystemen worden nu opgevangen in de Hub.
Wil jij een future proof architectuur?
- Voor €1000,- berekenen wij binnen 1 dag de business case
- Bij software aanschaf wordt deze €1000,- in mindering gebracht
- No Cure, No Pay

Deze aanbieding is geldig tot en met 31 mei 2018.







