Qlik’s data trends 2024

De wereld van data is de afgelopen jaren sterk in ontwikkeling. Zeker met de opkomst van kunstmatige intelligentie in allerlei verschillende vormen zal deze ontwikkeling de komende jaren alleen nog maar meer versnellen. Dat maakt het dan ook lastig om te voorspellen wat er op ons af gaat komen. Om ons daarin te helpen heeft Qlik hun trendwatcher Dan Sommer gevraagd wat de top 10 trends in data en AI zijn. Hij maakte daarover onder andere dit webinar. Het webinar is het kijken waard, maar in dit blog loopt Senior Consultant Lennaert van den Brink je door de 10 trends heen en bekijkt wat deze trends voor jou betekenen.
De 5 V’s
De uitdagingen die horen bij Big Data worden traditioneel omschreven door de zogeheten 3 V’s: “Volume”, “Velocity” en “Variety”.
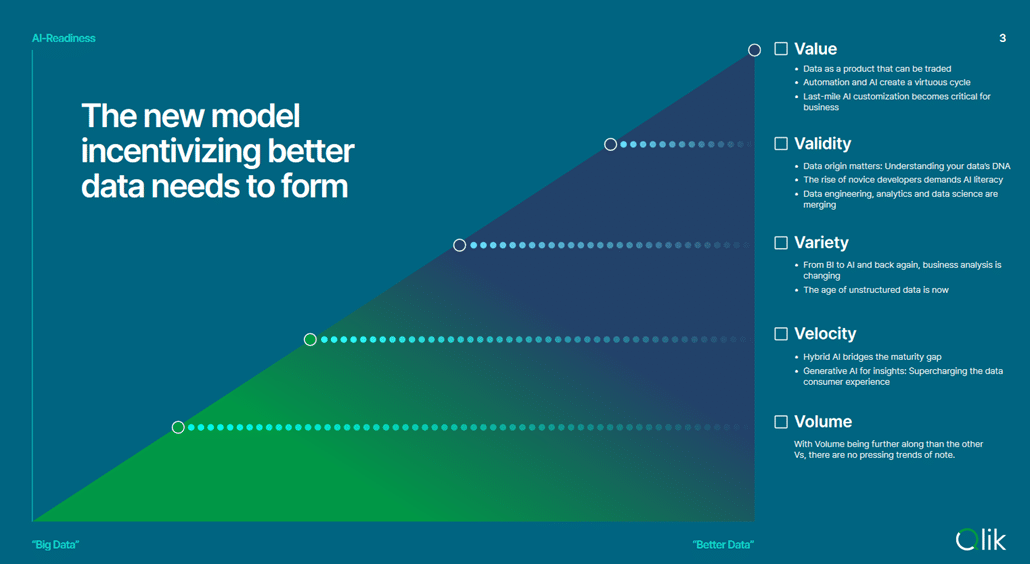
Volume
Volume verwijst naar de hoeveelheid data. Grotere volumes van data vragen om een ander soort opslag. De doorsnee harde schijf van een server is niet voldoende om de terrabytes aan data op te slaan die horen bij Big Data.
Velocity
Velocity gaat over de verwerkingssnelheid. De grote hoeveelheid data doorrekenen kost tijd. Hoe groter het datavolume hoe langer het verwerken kan duren. De uitdagingen die geassocieerd worden met Volume en Velocity zijn dan ook een belangrijke reden waarom zo veel organisaties tegenwoordig gebruik maken van de verschillende Cloud providers. Het is niet meer realistisch om de nodige rekenkracht zelf op te bouwen in het serverhok van je magazijn.
Variety
Variety gaat over de verschillende vormen die data aan kan nemen. Waar vroeger bijna alle data de vorm van gestructureerde tabellen had heb je tegenwoordig ook allerlei ongestructureerde data, zoals foto’s en video’s, maar ook in de vorm van bijvoorbeeld Tweets en andere social media berichten. Generatieve AI, zoals bijvoorbeeld ChatGPT, zal er voor gaan zorgen dat ongestructureerde data steeds beter en eenvoudiger te gebruiken is in allerlei bedrijfsprocessen.
Naast de traditionele 3V’s stelt Dan Sommer voor om 2 nieuwe V’s te introduceren: “Validity” en “Value”.
Validity
Validity gaat over de betrouwbaarheid van data. Data komt tegenwoordig uit veel verschillende bronnen en wordt door allerlei mensen en machines op verschillende niveaus verwerkt. Als we moeten gaan vertrouwen op onze data, dan is het van essentieel belang dat we snappen waar onze data vandaan komt en hoe het tot stand is gekomen.
Value
Value gaat over de waarde die de data kan vertegenwoordigen. Niet alleen kan data waarde hebben omdat het ons inzicht geeft in de performance van onze KPI’s, in de nabije toekomst zullen we steeds vaker gaan zien dat data ook als product verkocht zal worden. Grote techbedrijven zoals Facebook en Google hebben hier al een verdienmodel van gemaakt, zij verkopen data over hun gebruikers aan adverteerders, maar ook op kleinere niveaus zal de handel in goede, kwalitatieve waarde steeds meer toenemen. Dit effect wordt extra versterkt door de opkomst van generatieve AI en Large Language Models (LLMs). De huidige LLM’s zijn vooral generiek. Ze zijn getraind op grote hoeveelheden generieke data. De volgende stap zal echter zijn om dergelijke modellen te fine-tunen voor jouw specifieke context. Denk bijvoorbeeld aan een ChatGPT achtige toepassing die volledig getraind is op alle documentatie en software code die in jouw bedrijf is geschreven. Heb je als bedrijf echter nog niet zo veel kwalitatief goede documentatie of code dan kan het aantrekkelijk zijn dergelijke data van een externe partij in te kopen.
Wat betekent dit voor jouw bedrijf
Net als met de voorgaande data trends zal ook dit keer niet iedereen gelijk all-in gaan door grote AI-projecten op te starten in zijn of haar organisatie. Toch is het wel verstandig om nu al in te spelen op de trends.
Aan de slag met de kwaliteit van je data
Zo is het verstandig om nu al aan de slag te gaan met de kwaliteit van jouw data. Een goede datakwaliteit was al belangrijk voor de bestaande BI-rapportages en dashboards, maar het belang gaat alleen nog maar groter worden. Gelukkig schreven we eerder al een blog over hoe je aan de slag kunt gaan met datakwaliteit in jouw organisatie
Ongestructureerde data
Daarnaast is het goed om te beseffen dat ongestructureerde data steeds beter te gebruiken wordt. Op dit moment kan je misschien nog niet zo heel eenvoudig waarde halen uit documenten, foto’s, video’s en tweets, maar het gaat niet lang meer duren voordat er kant-en-klare toepassingen komen. Denk dus nu alvast na over welke ongestructureerde data je misschien nog niet vast legt, maar waar misschien wel nuttige inzichten uit te halen zijn. Door nu vast te beginnen met gestructureerde opslag van dit soort data kun je straks mee met de golf aan nieuwe toepassingen.
Data professionals
Tot slot laten de trends zien dat er heel wat gaat veranderen op het vlak van data professionals. De grenzen tussen rollen als data engineer, data scientist en data analist zullen steeds meer gaan vervagen en ook zullen er steeds meer data en AI-vaardigheden worden gevraagd van alle medewerkers op alle niveaus. Het is dus waarschijnlijk slim om jouw collega’s nu al te vragen om hun vaardigheden op data gebied aan te scherpen. Niet alleen op technisch vlak, maar bijvoorbeeld ook op het gebied van wet- en regelgeving is het noodzakelijk dat er voldoende kennis in huis is om op een veilige en verantwoorde manier om te kunnen gaan met alle nieuwe mogelijkheden die geboden worden.
Op de hoogte blijven van Qlik updates?
Op de hoogte blijven van de ontwikkelingen binnen Qlik? Schrijf je dan in voor onze nieuwsbrief en krijg alle ontwikkelingen direct in je inbox.

Geschreven door Lennaert van den Brink
Senior Consultant







