Datakwaliteit in Qlik Data Products: Trust Scores, eigen regels en AI-gedreven inzichten

In deel 2 van deze serie keken we naar het bouwen van een dataproduct in Qlik: datasets registreren, het product structureren, eigenaarschap toewijzen en het publiceren op de Marketplace. We sloten dat blog af met een waarschuwing: een goed gestructureerd product gevuld met onnauwkeurige of verouderde data is aantoonbaar slechter dan helemaal geen product, omdat het een vals gevoel van vertrouwen creëert. Maar hoe weet je of jouw dataproduct van goede kwaliteit is?
Ik schreef eerder al een blog over het onderwerp datakwaliteit als concept, waarin we de theoretische basis hebben gelegd over de onderliggende concepten. Mocht je die nog niet gelezen hebben, dan is dat een goed startpunt. In dit blog leggen we uit hoe Qlik’s dataproduct-functionaliteit datakwaliteit tot leven brengt binnen het platform.
De Qlik Trust Score
Qlik’s antwoord op de uitdaging van datakwaliteitsmeting is de Trust Score: een samengestelde, configureerbare score die elke dataset een kwaliteitsbeoordeling geeft op basis van meerdere dimensies. De score wordt prominent weergegeven in de dataproduct-interface en geeft afnemers direct een signaal over hoeveel ze op de data kunnen vertrouwen voordat ze ermee aan de slag gaan.
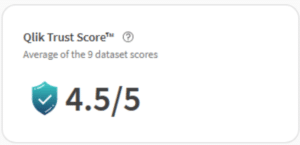
De Trust Score is geëvolueerd van de oorspronkelijke Talend Trust Score, die vijf dimensies omvatte, naar een raamwerk met zeven dimensies. Twee dimensies zijn verplicht en worden altijd berekend; de overige vijf zijn optioneel. De score kan worden weergegeven als een beoordeling uit 5 of als een percentage, afhankelijk van wat jouw organisatie het meest intuïtief vindt.
Voordat we de afzonderlijke dimensies bespreken, zijn twee dingen de moeite waard om alvast te benoemen. Ten eerste: de gekleurde kwaliteitsbalk die je ziet in het dataset-overzicht is niet hetzelfde als de volledige Trust Score. Die balk vertegenwoordigt alleen de twee verplichte dimensies (Geldigheid en Volledigheid) en is een snelle visuele samenvatting. Om het complete beeld te zien, moet je een dataset direct openen. Ten tweede: de Trust Score is beschikbaar op Qlik Talend Cloud Enterprise- en Premium-abonnementen, en op Qlik Cloud Analytics Premium- en Enterprise-tiers.
De Trust Score configureren
De configuratie van de Trust Score wordt centraal beheerd via Data Integration > Data quality > Qlik Trust Score in het platform. Hier kun je de optionele dimensies in- of uitschakelen en het gewicht van elke actieve dimensie instellen, waarbij alle gewichten optellen tot 100%. De configuratie geldt voor alle datasets in je gehele tenant, niet voor afzonderlijke dataproducten. Als je besluit dat Tijdigheid 30% van het gewicht krijgt, geldt dat voor elke dataset in je omgeving.
Tijdigheid en Diversiteit vormen in één specifiek opzicht een uitzondering op deze globale regel: beide bieden een per-dataset drempelconfiguratie. Voor Tijdigheid stel je per dataset de maximaal acceptabele ouderdom van de data in, zodat het gewicht globaal hetzelfde is maar de definitie van ‘vers genoeg’ per dataset kan variëren. Voor Diversiteit configureer je het minimaal verwachte aantal velden en rijen per dataset. Het dimensiegewicht is nog steeds globaal; alleen de drempelwaarde verschilt. Het aanpassen van de dimensiegewichten en het weergaveformaat vereist toegang tot de beheerinstellingen voor datakwaliteit, wat doorgaans is voorbehouden aan tenantbeheerders.
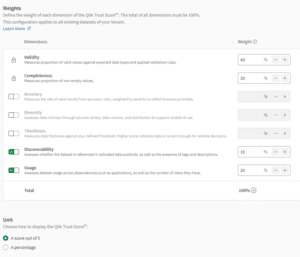
De zeven dimensies
Geldigheid en Volledigheid: het verplichte tweetal
Elke dataset in een Qlik dataproduct wordt beoordeeld op Geldigheid en Volledigheid, ongeacht hoe je de rest van de score hebt geconfigureerd. Geldigheid controleert of waarden de juiste opmaak en het juiste type hebben. Dit is waar Qlik’s semantische typen-functie veel werk doet. Als je kolom ‘E-mailadres’ waarden bevat die niet op e-mailadressen lijken, daalt de geldigheid. Volledigheid meet hoeveel data er ontbreekt: null-waarden, lege velden en inconsistente placeholders zoals ‘N/A’ of ‘Onbekend’ tellen allemaal mee als gemis. Een dataset waarbij 40% van het veld ‘Telefoonnummer klant’ leeg is, scoort slecht op volledigheid. Dat is precies het soort signaal dat je zichtbaar wilt hebben voordat afnemers er bovenop gaan bouwen.
De optionele dimensies
Naast het verplichte tweetal kun je tot vijf aanvullende dimensies inschakelen en bepalen hoeveel gewicht elk heeft in de totaalscore.
Nauwkeurigheid is waar eigen bedrijfsregels om de hoek komen kijken. In plaats van opmaak of aanwezigheid te controleren, evalueert nauwkeurigheid of waarden daadwerkelijk kloppen volgens de logica die jij definieert. Bijvoorbeeld: ‘omzet moet positief zijn’ of ‘einddatum moet later zijn dan startdatum’. Hoe je deze regels bouwt, bespreken we verderop in dit blog.
Tijdigheid meet of de dataset frequent genoeg wordt vernieuwd om bruikbaar te blijven. Je stelt per dataset de verwachte verversingsfrequentie in en Qlik signaleert wanneer de data niet op schema is bijgewerkt. Voor operationele datasets waar versheid cruciaal is, is deze dimensie de moeite waard om in te schakelen en zwaarder te laten wegen.
Vindbaarheid creëert een nuttige feedbackloop: het beloont datasets die goed gedocumenteerd en voorzien van de juiste tags zijn. Een dataset met een duidelijke beschrijving en relevante tags scoort beter dan een dataset zonder. Dit stimuleert direct het documentatiewerk dat in deel 2 aan bod kwam.
Gebruik houdt bij of de dataset daadwerkelijk wordt gebruikt in Qlik-apps en andere downstream tools. Een lage gebruiksscore betekent niet per se dat de data slecht is, maar het stelt wel een nuttige vraag: voorziet dit dataproduct in een echte behoefte?
Tot slot is Diversiteit primair gericht op AI-toepassingen. Het evalueert de variëteit, het volume en de verdeling van waarden in een dataset om te beoordelen hoe geschikt die is als trainings- of retrieval-data voor AI-applicaties. Als jouw dataproducts machine learning-modellen of RAG-gebaseerde tools zoals Qlik Answers voeden, is deze dimensie het overwegen waard.
Eigen datakwaliteitsregels
Geldigheid en Volledigheid geven je een solide basis, maar de dimensie Nauwkeurigheid is waar de Trust Score echt krachtig wordt voor jouw specifieke bedrijfscontext. Qlik ondersteunt twee soorten nauwkeurigheidsregels.
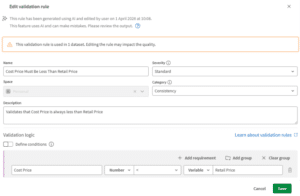
Globale regels worden gedefinieerd op tenant- of space-niveau en kunnen worden toegepast op meerdere datasets. Ze zijn ideaal voor organisatiebrede standaarden: ‘alle datumwaarden moeten in het verleden liggen’, ‘omzetwaarden moeten positief zijn’, ‘landcodes moeten twee tekens bevatten’. Je definieert ze op één plek en hergebruikt ze waar ze van toepassing zijn. Dataset-specifieke regels, zoals de naam al zegt, gelden voor één dataset en leggen logica vast die alleen in die context zinvol is, bijvoorbeeld controleren of een productcode een patroon volgt dat specifiek is voor jouw catalogus.
Beide typen worden gebouwd via een visuele regelbuilder: je selecteert de kolom of kolommen die je wilt valideren, kiest het type controle en bekijkt een voorbeeld van de resultaten op een steekproef van je data voordat je de regel bevestigt. Dit maakt het praktisch bruikbaar voor data stewards en analisten om regels aan te maken en te onderhouden.
Het is ook handig te weten dat elke regel een ernstniveau heeft: Kritiek, Groot, Standaard of Klein. Dit niveau bepaalt hoeveel een falende regel de totaalscore beïnvloedt. Een dataset met een paar kleine overtredingen scoort heel anders dan een dataset waarbij een kritieke regel faalt voor 40% van de records. Het doordacht instellen van ernstniveaus is onderdeel van het verkrijgen van betekenisvolle signalen uit de dimensie Nauwkeurigheid.
AI-suggesties voor regels
Soms is het lastig te verzinnen welke regels er van toepassing zouden moeten zijn op je dataset. In plaats van dit zelf vanuit het niets te moeten verzinnen, kan Qlik je dataset analyseren en proactief kwaliteitsregels voorstellen op basis van patronen die het in de data detecteert. Als een kolom consistent een bepaald formaat volgt, bijvoorbeeld een specifiek datumpatroon, een landcodestructuur, een numeriek bereik, dan zal Qlik een regel voorstellen om dat patroon te formaliseren en te handhaven.
Dit is op twee manieren nuttig. Ten eerste brengt het kwaliteitsproblemen aan het licht die je niet wist dat ze bestonden: kolommen waarvan je aannam dat ze schoon waren, maar waarbij uitzonderingen stilletjes zijn ingeslopen. Ten tweede verlaagt het de drempel om te starten met eigen regels aanzienlijk. Je hebt iets om op te reageren in plaats van iets te moeten verzinnen vanuit het niets.
Let op: AI-ondersteunde regelgeneratie vereist dat “cross-region inference” is ingeschakeld in jouw tenant, omdat Qlik’s GenAI-mogelijkheden data buiten jouw tenantregio verwerken (zie ook https://help.qlik.com/en-US/cloud-services/Subsystems/Hub/Content/Sense_Hub/Admin/cross-region-data-processing.htm).
De tenantbeheerder moet dit inschakelen in de beheerinstellingen als dat nog niet het geval is.
Semantische typen
Sommige kolommen in een dataset hebben speciale eisen. Een kolom als E-mail heeft vanuit de database een technisch datatype zoals bijvoorbeeld varchar(50), maar er zijn specifieke eigenschappen die het een mailadres maakt. Zo zal elk valide mailadres een @ bevatten en eindigen op een extensie zoals .nl of .com. E-mail is een zogeheten semantisch type, net als bijvoorbeeld een Telefoonnummer of een IBAN is. Qlik heeft standaard al een bibliotheek van ingebouwde semantische typen, maar biedt ook de mogelijkheid om eigen typen te maken via woordenboeken, reguliere-expressiepatronen of samengestelde typen. Zo kun je bijvoorbeeld een semantisch type maken dat valideert of de juiste afdelingsnamen van jouw bedrijf zijn gebruikt.
Wanneer een semantisch type aan een kolom wordt toegewezen, gebruikt Qlik dat voor de validiteit: ziet deze waarde eruit als een e-mailadres? Volgt dit telefoonnummer het juiste formaat voor Nederland? Dit maakt validiteit veel betekenisvoller dan simpelweg controleren of een kolom een niet-lege string bevat.
Wanneer kolommen zijn voorzien van semantische typen, kunnen gebruikers die in de Qlik Catalog zoeken filteren op het soort data dat een dataset bevat. Bijvoorbeeld: alle datasets vinden die een IBAN-kolom bevatten, zonder te hoeven weten hoe elke ontwikkelaar die kolom heeft benoemd. Tijd investeren in het toewijzen van semantische typen aan de sleutelkolommen in jouw dataproducten is een van de meest renderende dingen die je kunt doen om zowel je Trust Score als de algehele bruikbaarheid van je catalogus te verbeteren.
Zelf aan de slag
In dit blog hebben we laten zien hoe je aan de slag kunt met datakwaliteit in jouw eigen Qlik-omgeving:
- Registreer je datasets en laat Qlik de basisscores voor Geldigheid en Volledigheid berekenen. Identificeer eerst de voor de hand liggende problemen.
- Wijs semantische typen toe aan je sleutelkolommen. In het bijzonder identificatoren, datums en velden met specifieke formaatvereisten. Dit verbetert direct je Geldigheidsscore en de vindbaarheid van je catalogus.
- Werk samen met je tenantbeheerder om ervoor te zorgen dat de Trust Score-dimensies en -gewichten de prioriteiten van jouw organisatie weerspiegelen. Vergeet niet dat dit een globale instelling is, dus het is de moeite waard om met andere teams af te stemmen voordat je iets wijzigt.
- Voer de AI-regelsuggesties uit en evalueer ze op basis van jouw bedrijfscontext. Pas de zinvolle toe; verwerp of pas de rest aan. Zorg ervoor dat verwerking buiten de regio is ingeschakeld als je deze functie wilt gebruiken.
- Definieer eventuele aanvullende Nauwkeurigheidsregels voor bedrijfslogica die de AI niet zal kennen. Stel ernstniveaus doordacht in zodat de score de werkelijke impact van elke overtreding weerspiegelt.
- Configureer per-dataset Tijdigheidsdrempels voor datasets waarbij versheid cruciaal is.
- Zorg ervoor dat de documentatie van je dataproduct bekende kwaliteitsproblemen of -beperkingen vermeldt. Transparantie is onderdeel van betrouwbaarheid.
Volgende keer: je dataproduct in gebruik
Met een goed gebouwd dataproduct en een geloofwaardige Trust Score ben je klaar voor de laatste vraag: hoe kunnen de dataproducten in Qlik worden gebruikt door de eindgebruikers? In deel 4 bespreken we de Data Marketplace vanuit het perspectief van de afnemer en laten we zien hoe analisten in slechts een paar klikken van het ontdekken van een dataproduct naar een werkende Qlik Sense-app kunnen gaan, en hoe API-endpoints werken, inclusief de documentatiemogelijkheden, filteropties en de beperkingen die je moet kennen. Tot dan!
Contact
Benieuwd hoe je datakwaliteit structureel kunt verbeteren en vertrouwen in je dataproducten kunt vergroten? Met de Qlik Trust Score, eigen kwaliteitsregels en slimme inzet van AI zet je concrete stappen richting betrouwbare data.
Bij E-mergo helpen we organisaties bij het inrichten van datakwaliteit, het opzetten van dataproducten en het optimaal benutten van het Qlik-platform.
Wil je hierover sparren of zien hoe dit er in de praktijk uitziet? Neem gerust contact met ons op, we denken graag met je mee.
Blijf op de hoogte
Wil je geen blog missen? Schrijf je dan in voor onze nieuwsbrief. Zo ontvang je elke maand alle nieuwste content direct in je mailbox. Je kunt je inschrijven via de knop hieronder.

Geschreven door Lennaert van den Brink
Cluster Manager/Senior BI Consultant







