Je Qlik dataproduct aan het werk: de Marketplace, dashboards en API’s

In de drie vorige blogs van deze serie hebben we het concept van dataproducten besproken, hoe je er een bouwt in Qlik en hoe je de data erin betrouwbaar maakt. Maar een dataproduct dat niemand gebruikt is gewoon een heel goed georganiseerde plank. In dit laatste blog staat de afnemer centraal: hoe ontdekken gebruikers jouw dataproduct, hoe bouwen ze ermee en hoe stel je jouw data beschikbaar als API-endpoint voor applicaties buiten Qlik?
De Data Marketplace
Zie de Data Marketplace als de etalage van jouw dataproduct-ecosysteem. Het is een selfservice discovery-laag binnen Qlik Cloud waar zakelijke gebruikers en analisten beschikbare dataproducten kunnen bekijken, de kwaliteit en relevantie beoordelen en direct aan de slag gaan, zonder het datateam te hoeven raadplegen of door de technische complexiteit van de catalog te hoeven navigeren.
Wanneer een gebruiker de Marketplace opent, ziet die een doorzoekbaar, filterbaar overzicht van alle dataproducten waartoe toegang bestaat. Per product zijn de naam, beschrijving en het domein zichtbaar, de bijbehorende datasets en hun Trust Scores, lineage-informatie, de documentatie van de data product manager en contactgegevens van de eigenaar. Van daaruit kan de gebruiker direct actie ondernemen, waaronder het aanmaken van een analytics-app rechtstreeks vanuit het product. De zoek- en filtermogelijkheden laten gebruikers verfijnen op domein, kwaliteitsscore, datatype en meer. Dit is waar de investeringen uit deel 2 en deel 3 direct renderen: goed gedocumenteerde, kwalitatief hoogwaardige producten zijn veel makkelijker te vinden en veel eerder de keuze.
Publiceren op de Marketplace
Een dataproduct publiceren op de Marketplace vereist dat je het activeert vanuit de Data Product-beheerinterface. Tijdens de activering selecteer je de managed space waar de gepubliceerde kopie verschijnt en gebruikers met de ‘Can Consume’-rol in die space kunnen het product dan zien. Belangrijk om te begrijpen: activeren publiceert een kopie naar de geselecteerde managed space, maar de onderliggende datasets blijven op hun oorspronkelijke locatie. De Marketplace is een discovery- en toegangslaag, geen dataverschuivingsmechanisme.
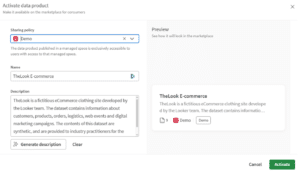
Het publiceren van een dataproduct vereist de Data Product Manager-rol, en de Marketplace-functie is beschikbaar op Qlik Cloud Analytics Premium- en Enterprise-abonnementen, en op Qlik Talend Cloud Premium en Enterprise. Weet je niet zeker wat op jouw omgeving van toepassing is? Vraag het aan je Qlik-beheerder.
Een Qlik Sense-app aanmaken vanuit een dataproduct
Dit is waar de gemiddelde Qlik-analist direct de waarde van ziet. Vanuit de Marketplace kan een gebruiker met één klik een nieuwe Qlik Sense-app aanmaken op basis van een dataproduct. Qlik laadt dan de datasets in de app, lost de associaties tussen tabellen automatisch op op basis van de relaties die in het product zijn gedefinieerd, en zet de gebruiker direct in de vertrouwde app-ontwikkelomgeving, klaar om te beginnen met het bouwen van visualisaties.
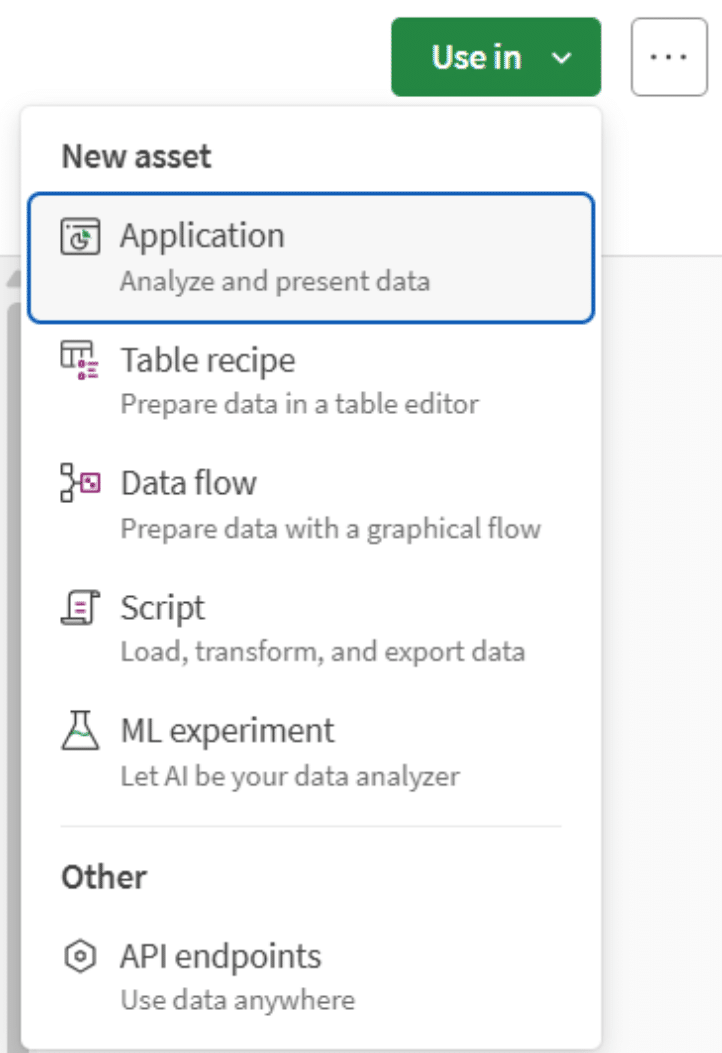
Voor teams die voorheen data moesten opvragen bij een data-engineer, een verbinding moesten instellen, moesten uitzoeken welke QVDs ze moesten laden en associaties handmatig moesten definiëren, is dit een betekenisvolle stap voorwaarts. Gebruikers met de ‘Can Consume’-rol kunnen dit alles doen zonder scripting-vaardigheden of kennis van de onderliggende data-architectuur. De kwaliteitsmeetwaarden die ze in de Marketplace zagen, zijn zichtbaar in de data waarmee ze werken. Ze starten dus met vertrouwen in plaats van twijfel.
Een praktische tip voor data product managers: zorg ervoor dat de associaties tussen datasets goed zijn gedefinieerd voordat je publiceert. Een analist die een app aanmaakt en merkt dat de tabellen niet koppelen zoals verwacht, verliest snel het vertrouwen in het product, ook als de data zelf prima in orde is. Als de relaties niet vanzelfsprekend zijn op basis van kolomnamen, documenteer ze dan in de productbeschrijving.
API-endpoints: verder dan Qlik
Dit is een functie die Qlik-gebruikers vaak verrast: dataproducten kunnen datasets blootstellen als API-endpoints. Dat betekent dat de data die je zorgvuldig hebt samengesteld, gedocumenteerd en op kwaliteit gecontroleerd, niet alleen door Qlik Sense-apps kan worden gebruikt, maar door elke applicatie die een HTTP-verzoek kan sturen. Denk aan maatwerkapplicaties van ontwikkelaars, Python- of R-scripts van data scientists, operationele systemen die periodiek data nodig hebben of andere BI-tools. Je QVDs en datasets worden een service.
Een endpoint aanmaken
Het activeren van een API-endpoint is eenvoudig: navigeer binnen het dataproduct naar Edit > API endpoints, selecteer de datasets die je wilt blootstellen en sla op. Dat is de volledige configuratie in de interface. Qlik genereert vervolgens een OData-endpoint voor elke geselecteerde dataset en produceert automatisch een OpenAPI-compatibele specificatie op basis van de dataset-metadata, zodat ontwikkelaars direct kunnen zien wat het endpoint teruggeeft en hoe ze het moeten aanroepen, zonder dat ze iemand hoeven te vragen. Als je hebt geïnvesteerd in goede kolombeschrijvingen en semantische typen in deel 3, betaalt die investering zich hier ook uit.
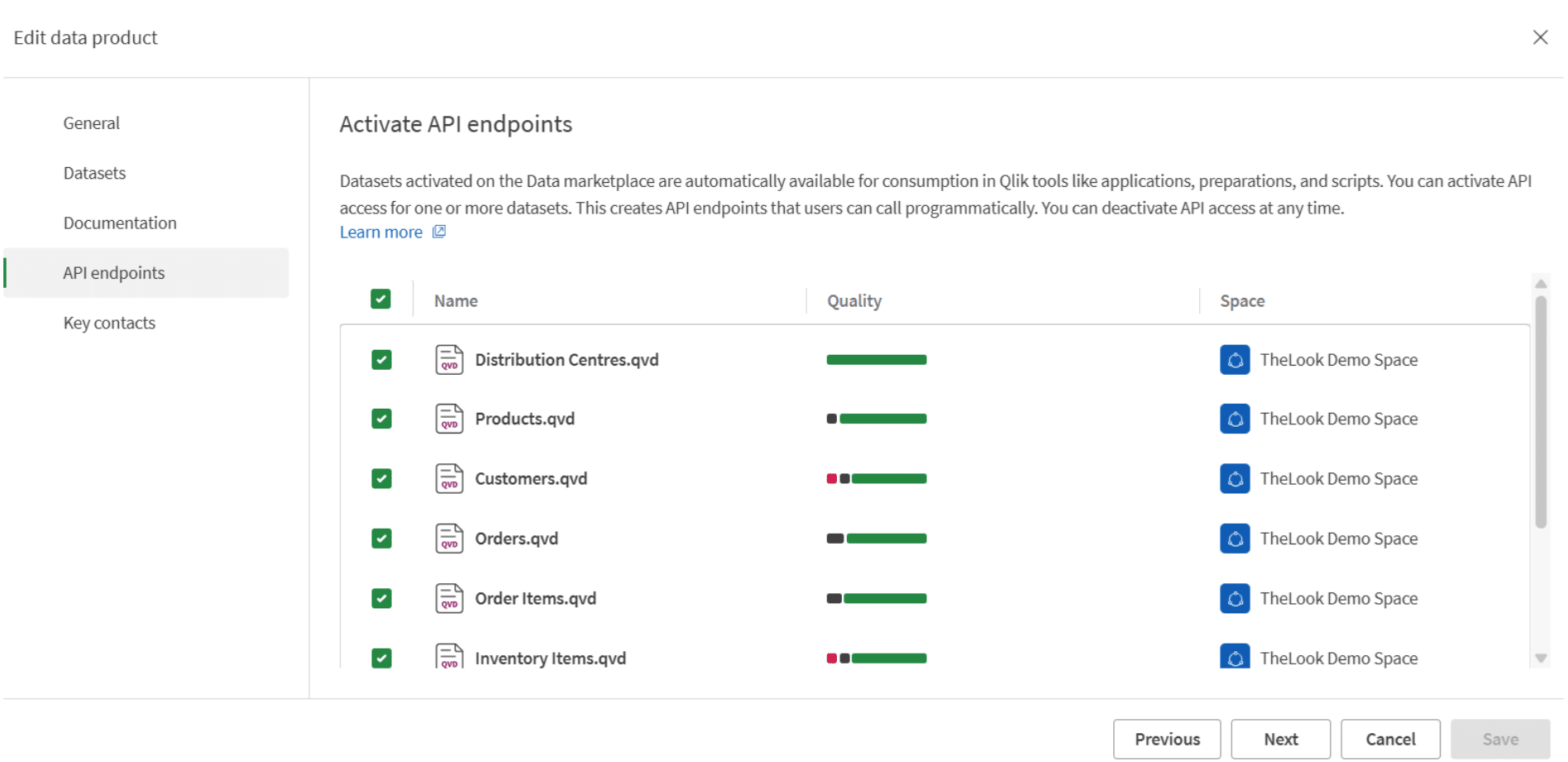
Omdat de endpoints het OData-protocol gebruiken, kunnen afnemers filterexpressies rechtstreeks in de query-URL toevoegen wanneer ze de API aanroepen. Zo kun je bijvoorbeeld een Sales Transactions-dataset filteren op datumbereik of regio zonder de volledige dataset op te halen. Hieronder zie je hoe zo’n aanroep er uitziet, gefilterd op records waarbij de regio Europa is en de orderdatum binnen 2025 valt:
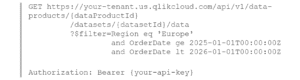
OData gebruikt standaard vergelijkingsoperatoren: eq (gelijk aan), ge (groter dan of gelijk aan), lt (kleiner dan). Meerdere condities worden gecombineerd met and. Datums volgen het ISO 8601-formaat. Stringwaarden staan tussen enkele aanhalingstekens. Deze filtering wordt volledig aan de kant van de afnemer afgehandeld op het moment van de aanroep en wordt niet vooraf geconfigureerd in het dataproduct. Het loont om in de endpoint-documentatie bij te houden welke velden het meest nuttig zijn om op te filteren, zodat afnemers efficiënt query’s kunnen uitvoeren.
Wat je moet weten voordat je een endpoint publiceert
Toegang tot API-endpoints wordt bepaald door dezelfde space-gebaseerde rechten als de rest van Qlik Cloud. Elke aanroep moet geauthenticeerd zijn en er zijn geen publieke of anonieme endpoints. De API geeft data terug zoals die tijdens de laatste reload was geladen. Als versheid belangrijk is voor jouw afnemers, zorg er dan voor dat je herlaadschema aan hun verwachtingen voldoet en maak die verversingsfrequentie zichtbaar in je endpoint-documentatie.
Het is ook goed om duidelijk te zijn over wat de API wel en niet afdwingt. Row-level security in Qlik wordt toegepast op het niveau van het laadscript van een app via Section Access, niet op dataset- of dataproduct-niveau. Dit betekent dat het API-endpoint geen row-level beperkingen afdwingt. Alle geauthenticeerde gebruikers met toegang tot het endpoint zien de volledige dataset zoals die is opgeslagen. Als row-level filtering een vereiste is voor jouw API-use case, moet die logica buiten het dataproduct worden afgehandeld.
Behandel het aanmaken van een API-endpoint tot slot met dezelfde zorgvuldigheid als het publiceren van een externe API. Definieer een duidelijk contract, documenteer het goed, beperk de blootgestelde kolommen tot wat afnemers werkelijk nodig hebben en communiceer wijzigingen ruim van tevoren.
Alles samen
In deze vier blogs hebben we veel terrein afgelegd: van het abstracte concept van een dataproduct en de Data Mesh-filosofie, via het bouwen en beheren van een dataproduct in Qlik, tot het ontsluiten ervan voor afnemers via de Marketplace en als API. Wat ik het meest inspirerend vind aan waar we zijn beland, is wie dit nu bereikt. Dataproducten in Qlik zijn niet langer alleen weggelegd voor organisaties met grote Talend Cloud-implementaties en toegewijde data-engineering teams. Als je een Qlik Cloud Analytics-omgeving hebt en een QVD-laag, heb je alles wat je nodig hebt om te starten.
Heb je deze serie gelezen en vraag je je af waar je nu precies moet beginnen? Hier is een kort stappenplan:
- Controleer of jouw Qlik-omgeving de Data Products-functionaliteit bevat en welke mogelijkheden beschikbaar zijn op jouw abonnementstype. Een gesprek met je Qlik-beheerder beantwoordt dit snel.
- Identificeer één businessdomein waar datakwaliteit en vindbaarheid voor wrijving zorgen. Dat is je pilot.
- Registreer de sleuteldatasets voor dat domein in de Qlik Catalog. Zelfs zonder een volledig dataproduct zijn de catalogisering en kwaliteitsmeetwaarden direct waardevol.
- Bouw het dataproduct aan de hand van de stappen in deel 2. Begin simpel: drie tot vijf datasets, goede documentatie, duidelijk eigenaarschap.
- Wijs semantische typen toe, voer de AI-regelsuggesties uit en stel de verplichte kwaliteitsdimensies in zoals beschreven in deel 3.
- Activeer het product op de Marketplace en let goed op wat er gebeurt. Wie gebruikt het? Welke vragen komen er binnen? Wat ontbreekt er?
- Blijf itereren. Een dataproduct is een levend ding, geen eenmalige oplevering.
Als het gaat om dataproducten is de investering reëel. Goede dataproducten kosten tijd en organisatorische inzet om goed te bouwen. Maar de opbrengst is er ook: sneller inzicht, beter vertrouwen in data, minder duplicatie en een datafundament dat echt klaar is voor welk AI-initiatief er ook als volgende komt.
Contact
Vragen, opmerkingen en feedback zijn zoals altijd van harte welkom. En als je meer wilt weten over hoe E-mergo jouw organisatie kan helpen aan de slag te gaan met dataproducten, neem dan gerust contact op via LinkedIn of klik op de onderstaande button.
Blijf op de hoogte
Wil je geen blog missen? Schrijf je dan in voor onze nieuwsbrief. Zo ontvang je elke maand alle nieuwste content direct in je mailbox. Je kunt je inschrijven via de knop hieronder.

Geschreven door Lennaert van den Brink
Cluster Manager/Senior BI Consultant







