Statistiek valkuil #1: Cherry Picking

Er zijn veel argumenten om je beslissingen te laten leiden door data. “Cijfers liegen niet” wordt er vaak geroepen. Op het eerste gezicht is dat helemaal waar. Data is een onpartijdige weergave van de realiteit en een goede toets voor aannames en onderbuikgevoelens. Helaas is het niet altijd even makkelijk om data op de juiste manier te interpreteren. Niet voor niets wordt op Universiteiten in Nederland bijna zonder uitzondering een deel van het curriculum gevuld met statistiek lessen. Wie werkt met data loopt kans om in een van de vele valkuilen te trappen. In deze serie blogs zullen we daarom een aantal veel voorkomende valkuilen uitleggen en geven we je ook concrete tips om ze te omzeilen. In dit eerste blog bespreken we ‘Cherry Picking’.
Cherry Picking:
Misschien wel de meest bekende valkuil omdat deze ook vaak bewust misbruikt wordt. Cherry Picking betekent dat je precies die datapunten uit de set haalt die jouw verhaal het beste ondersteunen en de rest weglaat wanneer je het aan anderen presenteert. Een goed voorbeeld is dit fragment uit Zondag met Lubach van oktober 2016.
Het Nederlandse nieuws kopte groot: “Controle allochtoon door politie in 40% van de gevallen onterecht”. Dat klinkt vrij heftig, maar wanneer je kijkte naar het volledige onderzoek, dan zie je dat het slechts gaat om 12 van 29 bekeken gevallen in een set van 272 staandehoudingen. De onderzoekers in het rapport concludeerden zelf: “de kwantitatieve analyse laat zien dat er geen significante samenhang aanwezig is tussen het uiterlijk van burgers (…) en de interventiebeslissing”.
Het lastige van Cherry Picking is dat het niet altijd bewust is. Zo kun je op een dashboard bijvoorbeeld een KPI object tegen komen zoals deze:
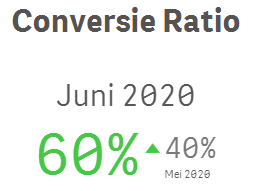
Vorige maand was de conversie 40% en deze maand 60%. Een enorme verbetering, het gaat goed! Maar wat nu als de grafiek over de afgelopen maanden er zo uit ziet?
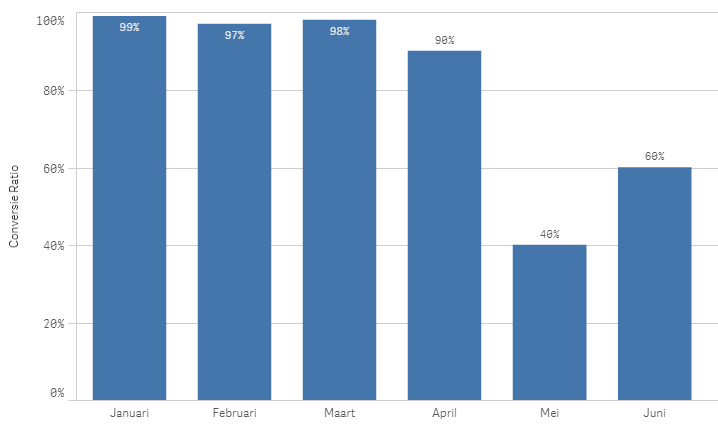
Die 40% van vorige maand is een enorme dip, deze maand zitten we op 60%, maar we zijn nog lang niet op de 97% die we het eerste kwartaal haalden. Het gaat dus helemaal nog niet goed! We moeten zo snel mogelijk aan de slag om de ratio weer op het oude niveau te krijgen. Of toch niet? Want wat als we ook de cijfers van vorig jaar er naast zetten?
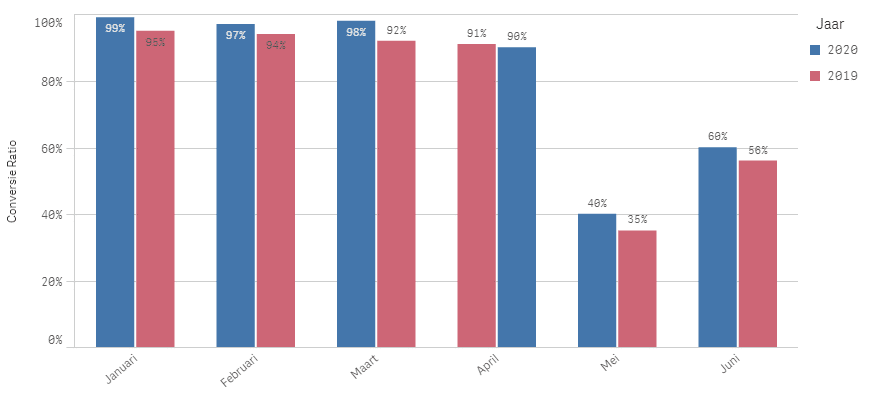
We hebben bijna elke maand een hogere conversie gehaald dan afgelopen jaar en de cijfers vertonen een vergelijkbaar patroon. Niks aan de hand dus, we doen het iets beter dan vorig jaar, maar de verschillen zijn klein.
Je kunt dus voor elke conclusie wel een visualisatie maken met dezelfde dataset. Best gevaarlijk, maar wat kun je doen om jezelf te wapenen tegen Cherry Picking? We geven je 3 tips:
#1 Stel vragen
Wanneer iemand jou data presenteert, vraag je zelf af: “Wat wordt me niet verteld? Heb ik genoeg context?”. Als je zelf toegang hebt tot de dataset is het vaak handig om zelf de data te verkennen. Een dashboard kan je hier bij helpen.
#2 Transparante filters
Maak duidelijk welke filtering je hebt toegepast wanneer je zelf data presenteert. In Qlik Sense staan bijvoorbeeld altijd de selecties boven in je scherm genoemd maar bij Power BI is dit niet altijd zo. Maak je zelf een export of rapportage, dan is het goed om hierbij te noteren welke selecties je hebt gebruikt.
#3 Definities
Zorg voor goede definities van KPI’s. Als je van te voren duidelijk met elkaar hebt afgesproken hoe prestatie indicatoren gemeten moeten worden wordt de ruimte om (bewust of onbewust) te cherrypicken aanzienlijk kleiner.
Meer statistiek valkuilen?
Ben je na het lezen van dit blog nieuwsgierig geworden naar de andere blogs uit deze serie? Lees alle blogs op je gemak terug via de buttons hieronder.

Geschreven door Lennaert van den Brink
Senior Consultant







