Statistiek valkuil #2: Geaggregeerde data

Er zijn veel argumenten om je beslissingen te laten leiden door data. “Cijfers liegen niet” wordt er vaak geroepen. Op het eerste gezicht is dat helemaal waar. Data is een onpartijdige weergave van de realiteit en een goede toets voor aannames en onderbuikgevoelens. Helaas is het niet altijd even makkelijk om data op de juiste manier te interpreteren. Niet voor niets wordt op Universiteiten in Nederland bijna zonder uitzondering een deel van het curriculum gevuld met statistiek lessen. Wie werkt met data loopt kans om in een van de vele valkuilen te trappen. In deze serie blogs zullen we een aantal veel voorkomende valkuilen uitleggen en geven we je ook concrete tips om ze te omzeilen.
Het gevaar van geaggregeerde data:
Op 4 augustus 2017 kwam de film “An Inconvenient Sequel: Truth to Power” uit, een vervolg op de hit documentaire van Al Gore. Ongeveer 25 dagen later had de film op de welbekende Internet Movie DataBase (IMDB) een score van 5.4 over een totaal van 2645 reviews. Een matige score waarmee de film niet per se heel hoog op het “te kijken” lijstje van menig filmliefhebber zal staan. Het interessante van deze score is echter dat het gemiddelde cijfer niet het hele verhaal lijkt te vertellen. Kijken we namelijk naar de verdeling van gegeven scores in een grafiek dan zien we het volgende:
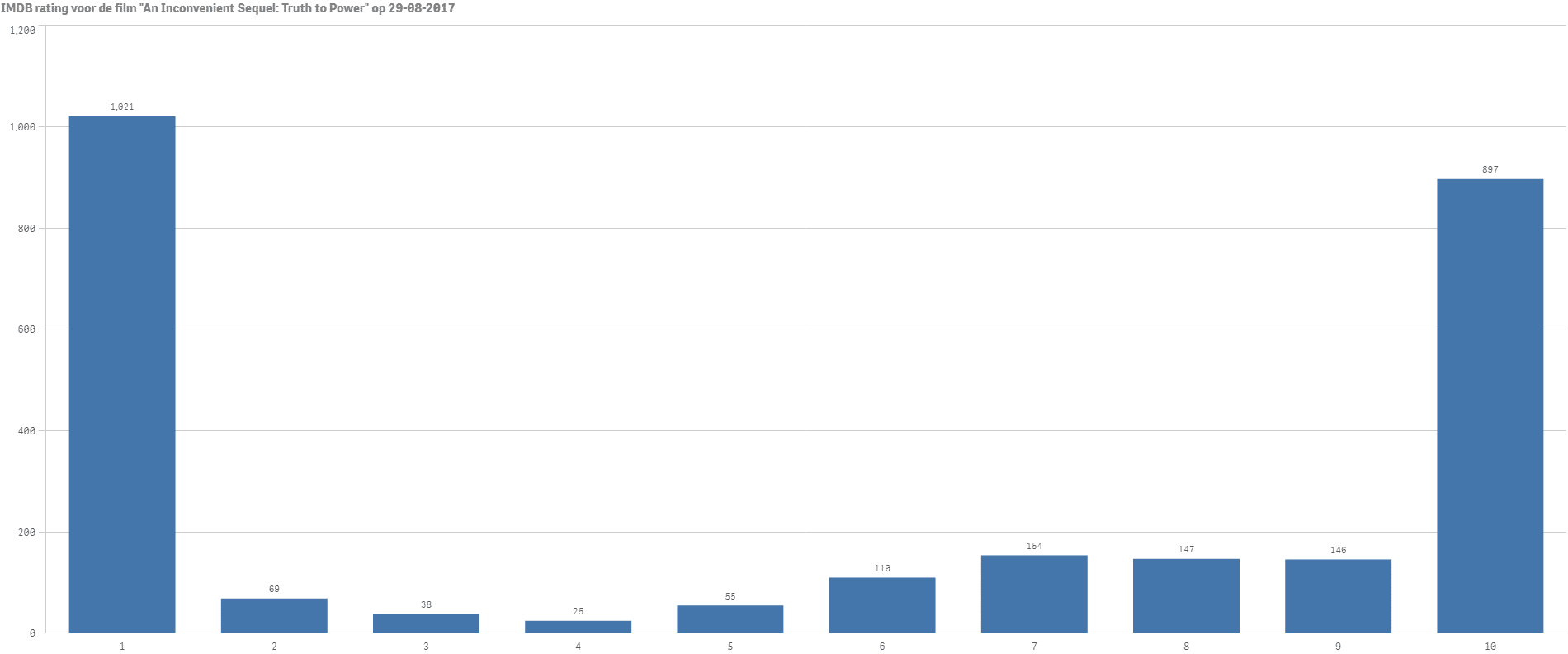
Zoals je kunt zien zijn de meningen over de film sterk verdeeld en werden vooral het cijfer 1 en 10 heel vaak gegeven. Als je de gemiddelde score gebruikt om te bepalen of de film het kijken waard is ga je dus waarschijnlijk de mist in, want de kans lijkt bijna fifty-fifty of je hem geweldig vindt of juist heel slecht. Onderzoekers van ABC news vonden destijds dat er grote verschillen waren in de meningen van critici versus publiek, man versus vrouw en zelfs mensen die de film wel gezien hebben en mensen die hem niet hebben gezien.
Het voorbeeld van de film van Al Gore laat zien wat het gevaar is van het gebruiken van geaggregeerde meetwaarden. Het voordeel van dergelijke meetwaarden is dat het niet uit maakt hoe groot je dataset is, je kunt er altijd een samenvatting van geven met behulp van statistische formules. Maar zoals bij alle samenvattingen verlies je daarmee ook alle context. De wiskundige Anscombe liet in 1973 zien dat je datasets kunt construeren die als je ze samenvat met geaggregeerde meetwaarden exact de zelfde dataset lijken te zijn. Hij maakte 4 datasets die allen het zelfde gemiddelde hadden, maar ook de zelfde variantie en correlatie. Visualiseer je ze echter in een grafiek, dan zien de datasets er allemaal heel verschillend uit:
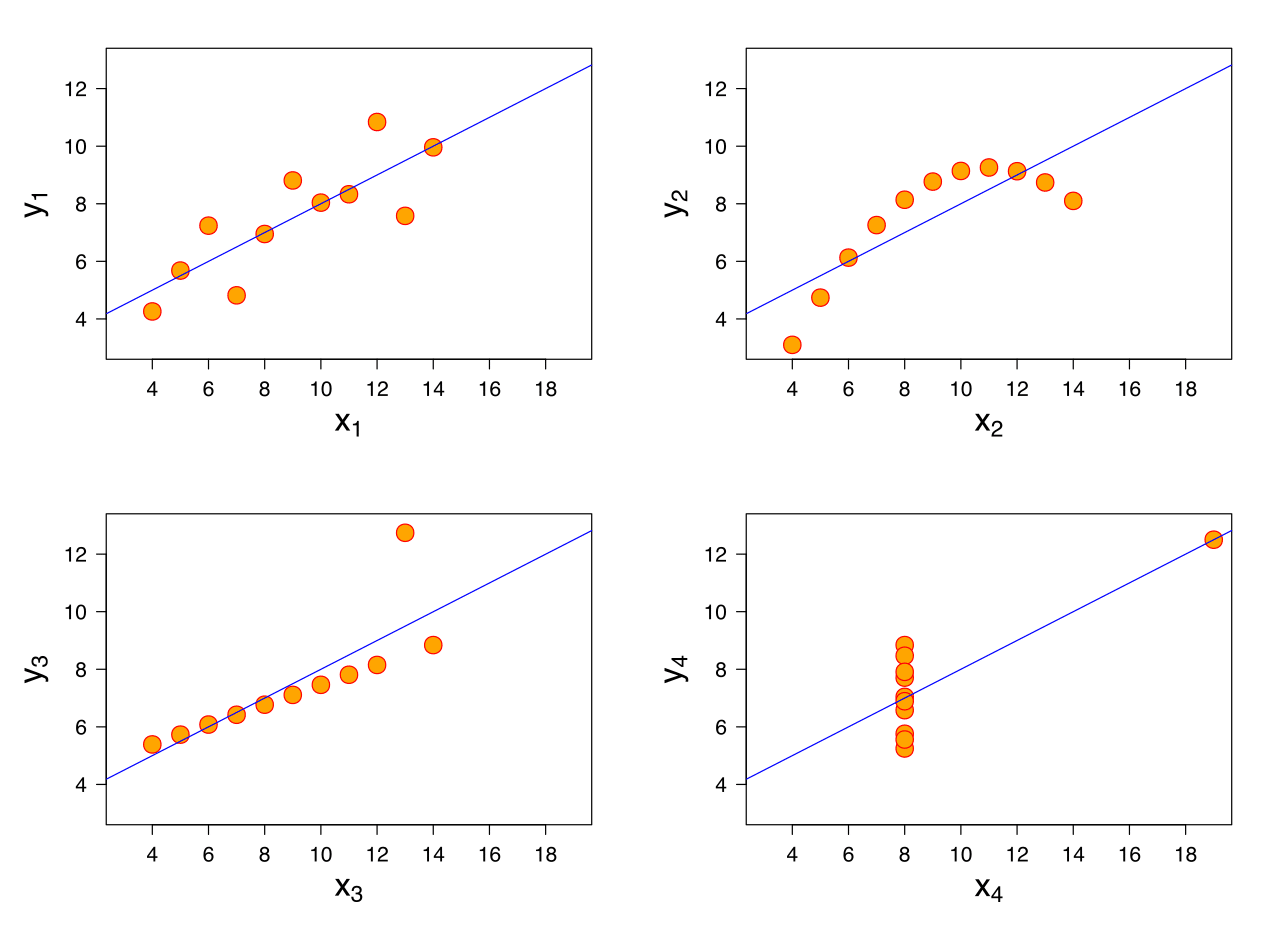
Zijn aggregaties dan “slecht”? Nee, niet per se. Net als elke andere samenvatting helpen ze je om snel een globaal idee te krijgen en kunnen ze je triggeren om op verder onderzoek uit te gaan. Sterker nog, soms zijn ze zelfs noodzakelijk om het totale plaatje te kunnen vormen. Een goed voorbeeld hiervan is de case van de Univeristy of Berkely. In de jaren 70 werd Berkely ervan beschuldigd dat zij zouden discrimineren op geslacht, vrouwen zouden structureel minder vaak worden toegelaten dan mannen. Van de Onderzoekers keken naar de data van de 6 grootste afdelingen van de universiteit en zagen het volgende:
| Afdeling | Man | Vrouw | ||
|---|---|---|---|---|
| Aangemeld | Toegelaten | Aangemeld | Toegelaten | |
| A | 825 | 62% | 108 | 82% |
| B | 560 | 63% | 25 | 68% |
| C | 325 | 37% | 593 | 34% |
| D | 417 | 33% | 375 | 35% |
| E | 191 | 28% | 393 | 24% |
| F | 373 | 6% | 341 | 7% |
| Totaal | 2691 | 45% | 1835 | 30% |
In de tabel zijn per afdeling de getallen onderstreept in de kolom waar ze het grootste zijn voor die categorie. Als je naar deze 6 afdelingen kijkt, lijkt het eigenlijk op het omgekeerde. Bij 4 van de 6 afdelingen werden procentueel meer vrouwen dan mannen toegelaten. Kijken we echter naar het totaal, dan zien we een bevestiging van de stelling dat mannen vaker worden toegelaten. Dit effect wordt ook wel Samson’s Paradox genoemd. Wat je hier ziet gebeuren is dat vrouwen zich vaker aanmeldden bij studies waar sowieso veel mensen worden afgewezen.
Zoals wel vaker is gebleken is de manier waarop je naar je data kijkt van groot belang voor het vormen van het juiste inzicht. Onderstaande tips kunnen je helpen om de valkuilen van geaggregeerde data te omzeilen:
#1 Samenvatting
Behandel een geaggregeerde meetwaarde ook echt als een samenvatting. Geef de gebruiker van je dashboard context door de data te visualiseren.
#2 Totalen
Door in een tabel een totaal regel toe te voegen maak je het makkelijker om een effect zoals die van Simson’s paradox te herkennen.
#3 Controleer grootte
Controleer je data op steekproef grootte. Simpson’s paradox treedt op wanneer je voor 1 dimensiewaarde veel meer waarnemingen hebt dan voor een andere dimensiewaarde.
Meer statistiek valkuilen?
Ben je na het lezen van dit blog nieuwsgierig geworden naar de andere blogs uit deze serie? Lees alle blogs op je gemak terug via de buttons hieronder.

Geschreven door Lennaert van den Brink
Senior Consultant







